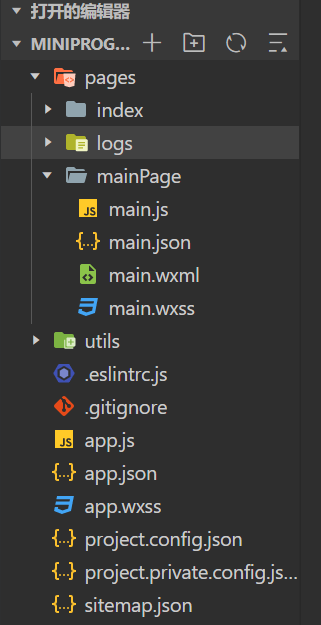
开启配置,先数据清洗,写了一个format.py,处理成可以处理的格式
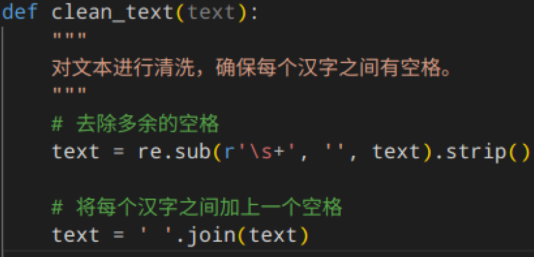
接着加入了一个函数,这样整个梳理,处理成正常形式
开始使用默认配置,单文件配置
./build/bin/lmplz -o 2 -S 10G < data/test/test.txt > models/test/test.arpa

简单优化一下n和内存,效果进步
./build/bin/lmplz -o 5 -S 15G < data/test/test.txt > models/test/test.arpa
接下来自然而然想到提高文本量,先尝试一下全文本训练效果
cat data/full/*.txt | ./build/bin/lmplz -o 4 -S 8G > models/full/full.arpa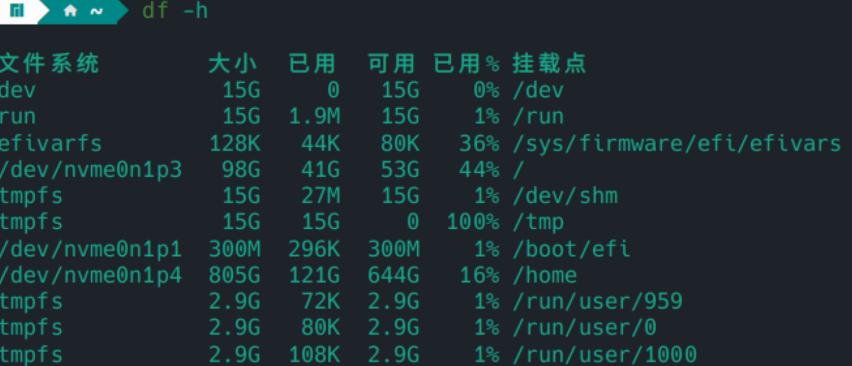
emmm结果果然在我小主机上炸了,根本没办法处理这样的事情
妥协,处理前100个
ls data/full/*.txt | head -n 100 | xargs cat | ./build/bin/lmplz -o 4 -S 8G > models/full/full.arpa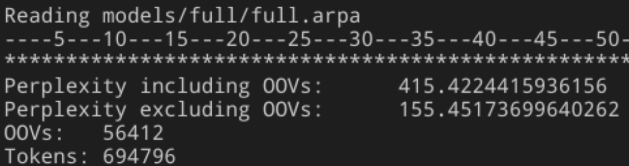
确实进步显著
那么多少个会炸开始疑惑我了,再试1000
ls data/full/*.txt | head -n 1000 | xargs cat | ./build/bin/lmplz -o 4 -S 8G > models/full/full.arpa
内存再次爆炸,最后试了个800,效果显著

使用服务器,全部跑完训练了一个,效果很好
cat data/full/*.txt | ./build/bin/lmplz -o 4 -S 10G > models/full/full.arpa

但模型大小也来到了20G,非常吓人,果然专业的东西交给专业服务器来跑
开足马力
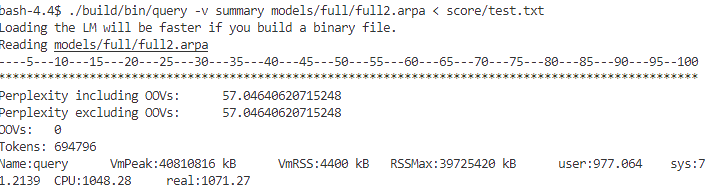
cat data/full/*.txt | ./build/bin/lmplz -o 5 -S 15G > models/full/full2.arpa
优化了一下预处理