入门
基础知识
Opengl:一个规范,包含了一系列可以操作图形、图像的函数。Opengl严格的规定了每一个函数应该如何执行,以及输出值,但是对于具体的实现可以自己实现,结果正确就可以。
立即渲染模式(Immediate mode,也就是固定渲染管线):绘图方便,容易理解,但是效率太低。已废止
核心模式:上手更难,要求使用现代函数。但提供了更多的灵活性,更高的效率,更重要的是可以更深入的理解图形编程。
扩展:当出新的渲染特性的时候,可以按照下面的方法,检查一下是否支持这个扩展,然后给与不同的实现。
if(GL_ARB_extension_name)
{
// 使用硬件支持的全新的现代特性
}
else
{
// 不支持此扩展: 用旧的方式去做
}状态机:OpenGL自身是一个巨大的状态机(State Machine)——一系列的变量描述OpenGL此刻应当如何运行
Start!
下载:https://www.glfw.org/download.html,选择64-bit windows,下载后解压,得到如下
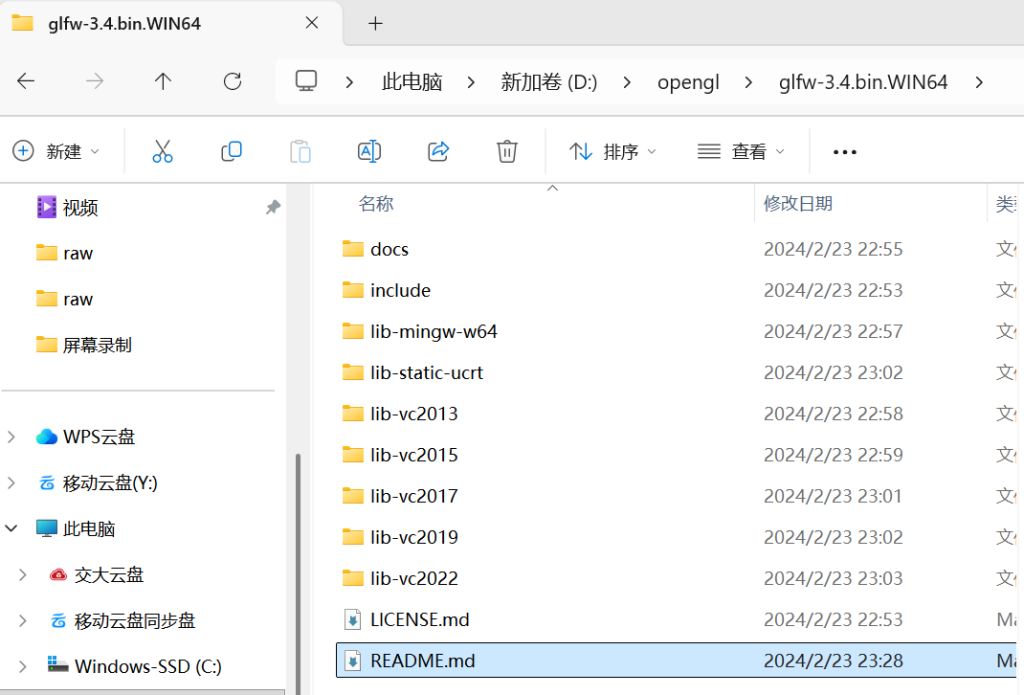
- include/
- 给你的项目
#include <GLFW/glfw3.h>用的“头文件目录” - 当然只包含申明,不包含实现,真正的实现来自于下面的库文件(
.a/.lib)或 DLL
- 给你的项目
- lib-mingw-w64/
- 使用MinGW用的时候,链接的库文件,Make 里写
target_link_directories(... lib-mingw-w64)后,target_link_libraries(... glfw3 或 glfw3dll)就会在这里找库
- 使用MinGW用的时候,链接的库文件,Make 里写
使用的话,需要创建一个CMake文件,然后调用。卸载别处,按照这个配置一下引入即可。
cmake_minimum_required(VERSION 3.20)
project(OpenGLDemo LANGUAGES CXX)
# 1) 使用 C++17
set(CMAKE_CXX_STANDARD 17)
set(CMAKE_CXX_STANDARD_REQUIRED ON)
# 2) 你的可执行程序(只编译一个 main.cpp)
add_executable(OpenGLDemo
src/main.cpp
)
# ========= GLFW 路径(你只需要改这里)=========
# 这是你下载的 glfw-3.4.bin.WIN64 解压后的根目录
set(GLFW_ROOT "D:/opengl/glfw-3.4.bin.WIN64")
# ============================================
# 3) 告诉编译器:去哪里找 glfw3.h
target_include_directories(OpenGLDemo PRIVATE
"${GLFW_ROOT}/include"
)
# 4) 告诉链接器:去哪里找 MinGW 的 .a 库文件(import/static)
target_link_directories(OpenGLDemo PRIVATE
"${GLFW_ROOT}/lib-mingw-w64"
)
# 5) 链接库
# - glfw3dll:对应 lib-mingw-w64 里的 libglfw3dll.a(动态库导入库)
# - opengl32:Windows 的 OpenGL 系统库
# - 其它:GLFW 在 Windows 下常需要的系统库
target_link_libraries(OpenGLDemo PRIVATE
glfw3dll
opengl32
gdi32
user32
shell32
winmm
)
# 6) 运行时需要 glfw3.dll:把它复制到 exe 同目录(否则会提示缺 DLL)
# 如果你的包里没有 bin/glfw3.dll,就把 dll 放哪儿就改哪儿
add_custom_command(TARGET OpenGLDemo POST_BUILD
COMMAND ${CMAKE_COMMAND} -E copy_if_different
"${GLFW_ROOT}/lib-mingw-w64/glfw3.dll"
"$<TARGET_FILE_DIR:OpenGLDemo>/glfw3.dll"
)Triangle
几个基本概念来说:
- VAO:顶点数组对象
- VBO:顶点缓冲对象
- EBO:元素缓冲对象
- IBO:索引缓冲对象
一个基本的图形渲染管线:
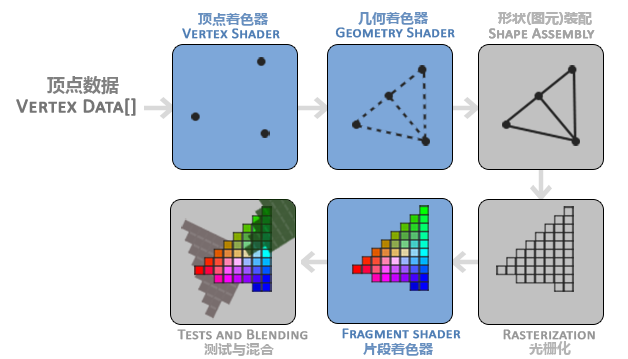
图元:用于提示指定渲染类型,如把一系列点最终绘制成什么。
- 顶点着色器
- 把3D坐标转换为另一种3D坐标,同时对顶点属性进行基本处理
- 几何着色器
- 对于顶点着色器阶段的顶点,可以选择性传递给几何着色器
- 几何着色器会把一组顶点作为输入,然后这些顶点形成图元,也可以发出新的顶点来形成图元或其他形状
- 对于顶点着色器阶段的顶点,可以选择性传递给几何着色器
- 图元配装:
- 将顶点着色器(或几何着色器)输出的所有顶点作为输入,然后装配成为指定的形状
- 装配好后就会传入光栅化阶段,进行光栅化。这里它会把图元映射为最终屏幕上相应的像素,生成供片段着色器(Fragment Shader)使用的片段(Fragment)。
- 在下一阶段片段着色器运行之前,会进行裁切。裁切会丢弃掉视图以外全部的像素,用来提高效率。
- 片段着色器
- 用于产生最终的颜色。包含着3D场景的各种数据(比如光照、阴影、光的颜色等等),这些数据可以被用来计算最终像素的颜色。
- 测试与混合
- 检测深度,决定最后是否渲染
- 检测alpha值(透明值),然后进行混合
对于绝大多数场合,只需要配置顶点和片段着色器就可以了。其它的看着默认就可以。
顶点输入
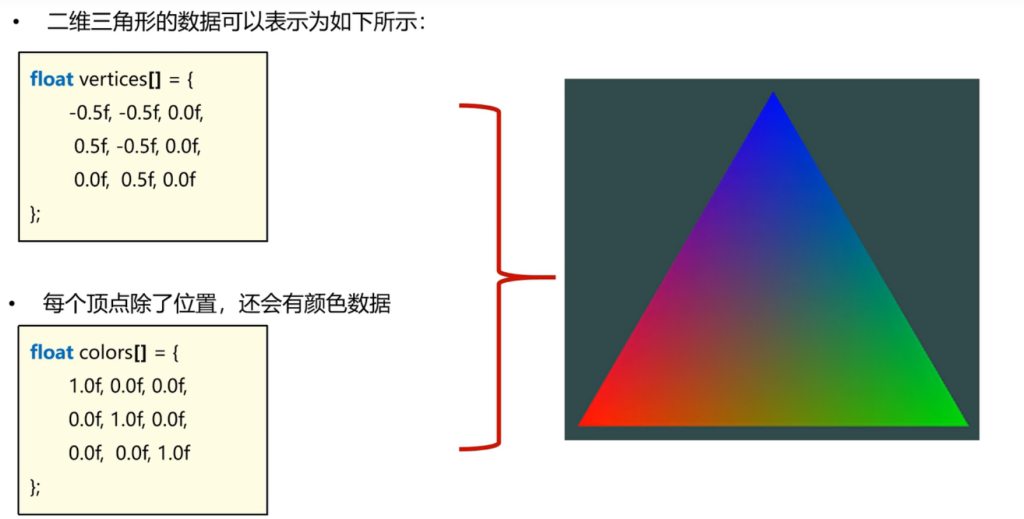
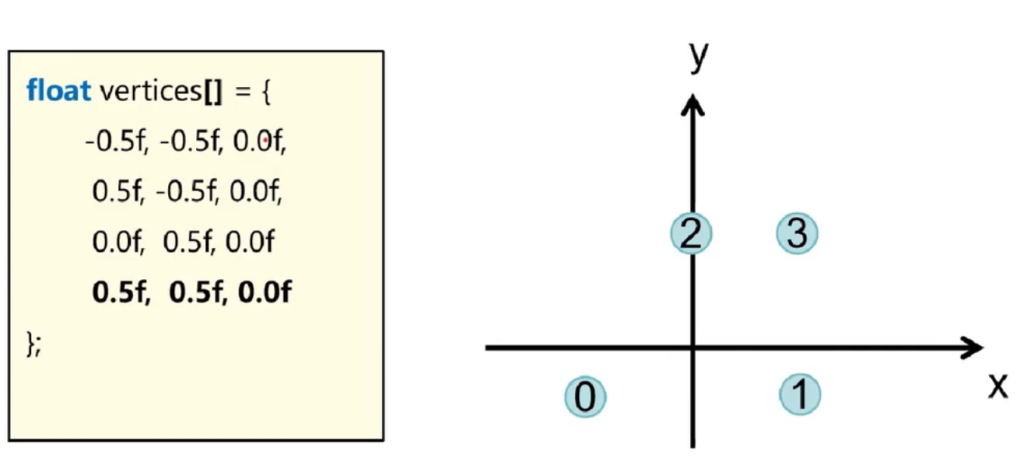
对于如果需要渲染一个三角形,那么可以定义一个形式如下:
float vertices[] = {
-0.5f, -0.5f, 0.0f,
0.5f, -0.5f, 0.0f,
0.0f, 0.5f, 0.0f
};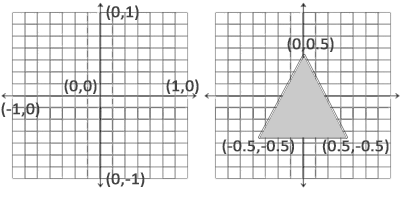
渲染成如上形状,这就是基本的原理。当然实际上坐标不可能直接用,还要取决于摄像头的观察和改变。
其余的参考计算机图形学,其实都差不多。下面开始学习编程
开始编程
创建窗体
- 1.初始化GLFW基本环境
glfwInit();
glfwWindowHint(GLFW_CONTEXT_VERSION_MAJOR, 3); //opengl主版本号
glfwWindowHint(GLFW_CONTEXT_VERSION_MINOR, 3); //opengl次版本号 合起来就是3.3版本;当然也可以按照同样的配置4.6版本
glfwWindowHint(GLFW_OPENGL_PROFILE, GLFW_OPENGL_CORE_PROFILE); //使用核心模式
- 2.创建窗口对象
GLFWwindow* window = glfwCreateWindow(800, 600, "LearnOpenGL", NULL, NULL);//创建窗口对象
glfwMakeContextCurrent(window);//设置当前窗口为opengl绘制的舞台
- 3.执行窗体循环
while(!glfwWindowShouldClose(window)) {
glfwPollEvents(); //每一帧时候,接收并分发窗口信息
}
glfwTerminate:用于退出程序
相关代码
#include <GLFW/glfw3.h>
#include <iostream>
int main()
{
// 1.初始化GLFW基本环境
glfwInit();
// 1.1 配置OpenGl主版本次版本号
glfwWindowHint(GLFW_CONTEXT_VERSION_MAJOR,4);
glfwWindowHint(GLFW_CONTEXT_VERSION_MINOR,6);
// 1.2 启用核心模式(非立即渲染模式,可以给与更多自由度)
glfwWindowHint(GLFW_OPENGL_PROFILE,GLFW_OPENGL_CORE_PROFILE);
// 2.创建窗体对象
GLFWwindow* window = glfwCreateWindow(800,600,"OpenglStudy",NULL,NULL);
//配置当前窗体对象对Opengl的绘制舞台
glfwMakeContextCurrent(window);
// 3.执行窗体循环
while(!glfwWindowShouldClose(window) ) {
// 接受并分发窗口消息
// 检查消息队列是否有需要处理的鼠标键盘等各种消息,如果有就清空队列
glfwPollEvents();
}
// 4.退出程序并做相关的清理
glfwTerminate();
}事件回调函数
事件回调函数:窗口激活的情况下,用于响应窗口变化键盘鼠标操作等信息的函数
那如何写窗口响应函数呢?那就是可以写一个回调函数,在发生变化时候产生回调
// 窗口尺寸变化后,回调的函数
void frameBufferSizeCallBack(GLFWwindow* window, int width, int height) {
std::cout << "窗口大小: " << width << " x " << height << std::endl;
}
// 加入监听设置,相当于注册一个回调吧
glfwSetFramebufferSizeCallback(window,frameBufferSizeCallBack);
// 加入键盘响应回调函数
void keyCallBack(GLFWwindow*window , int key , int scancode ,int action ,int mods) {
// key:字母键盘码,scancode:物理按键码,action:是否有按下or抬起,mods:是否有shift/ctrl
//键盘事件响应
// if(key == GLFW_KEY_W) // 按下了W
// if(action == GLFW_PRESS) // 按键按下
// if(action == GLFW_RELEASE) // 键位抬起
// if(mods == GLFW_MOD_CONTROL) // 按下control
std::cout << "按下了:" << key << std::endl;
}
// 加入键盘监听设置
glfwSetKeyCallback(window,keyCallBack);
函数加载
opengl是一个标准规范,而不是具体的实现。实现需要依靠厂商编写的驱动程序。具体来说,程序运行时候只有声明,具体的实现需要向显卡驱动查询出具体的位置,然后加载过来。

因此我们需要配置glad,如果没有的话,每一次所有的函数我们都去找实现,而通过glad可以方便的配置上
下载配置glad,glad的作用是根据不同的opengl版本获取驱动中的函数指针
GLFW:提供渲染物体所需要的最低限度的接口
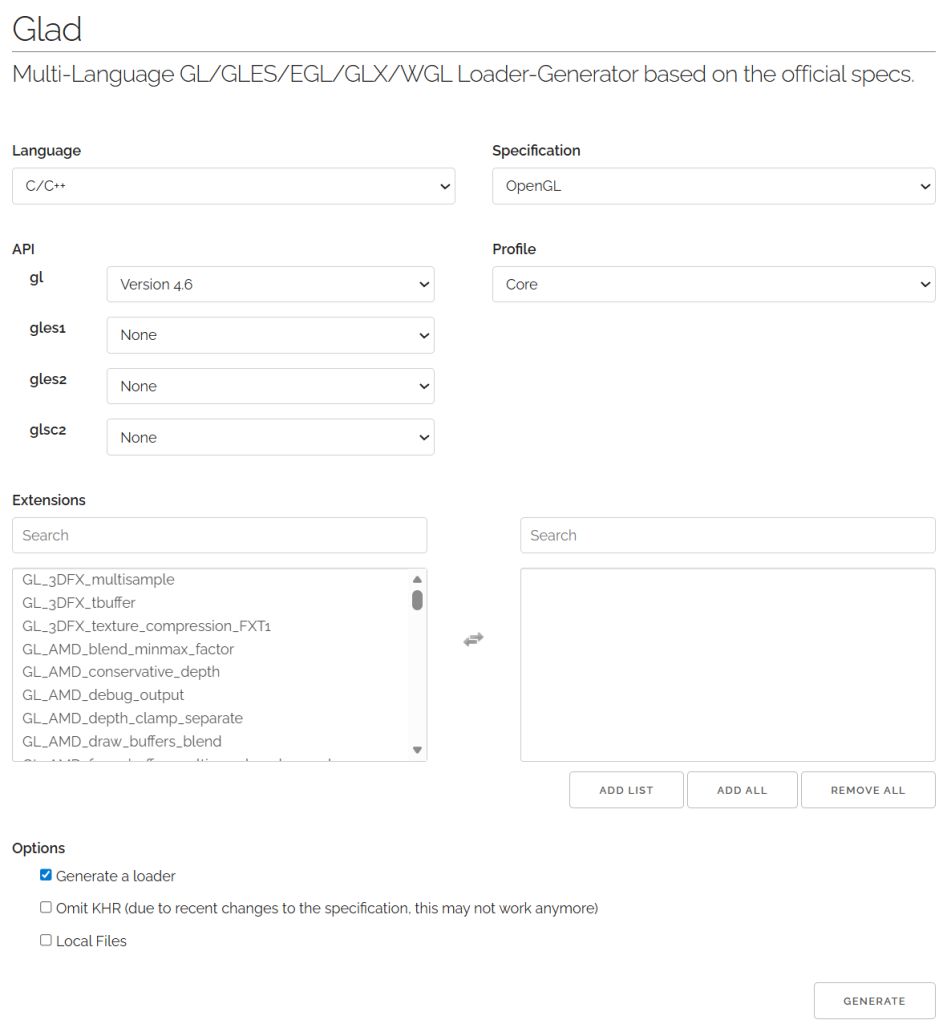
当然也可以不打开,下载上面这个就行,4.6版本的可以直接使用。配置成如下格式,记得同样写好cmakelist
配置完成后参考
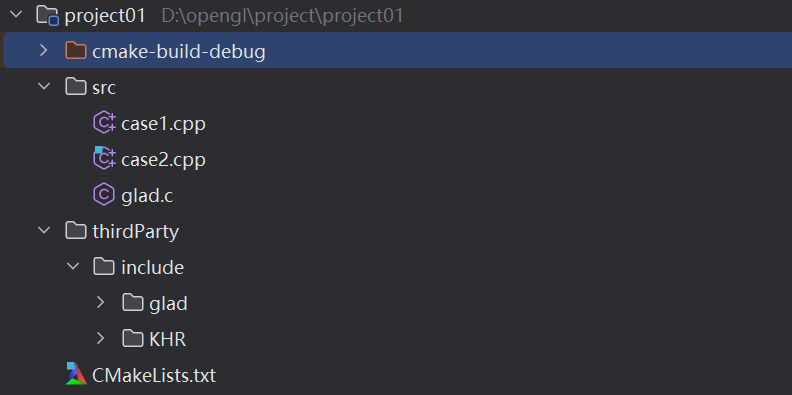
CMakeLists这里添加目录,引入程序
cmake_minimum_required(VERSION 3.20)
project(OpenGLDemo LANGUAGES C CXX)
# 1) 使用 C++17
set(CMAKE_CXX_STANDARD 17)
set(CMAKE_CXX_STANDARD_REQUIRED ON)
include_directories(
SYSTEM ${CMAKE_CURRENT_SOURCE_DIR}/thirdParty/include
)
# 2) 你的可执行程序(只编译一个 main.cpp)
# 配置选择当前所用的项目
add_executable(OpenGLDemo
src/case2.cpp
src/glad.c
)
# ========= GLFW 路径(你只需要改这里)=========
# 这是你下载的 glfw-3.4.bin.WIN64 解压后的根目录
set(GLFW_ROOT "D:/opengl/glfw-3.4.bin.WIN64")
# ============================================
# 3) 告诉编译器:去哪里找 glfw3.h
target_include_directories(OpenGLDemo PRIVATE
"${GLFW_ROOT}/include"
)
# 4) 告诉链接器:去哪里找 MinGW 的 .a 库文件(import/static)
target_link_directories(OpenGLDemo PRIVATE
"${GLFW_ROOT}/lib-mingw-w64"
)
# 5) 链接库
# - glfw3dll:对应 lib-mingw-w64 里的 libglfw3dll.a(动态库导入库)
# - opengl32:Windows 的 OpenGL 系统库
# - 其它:GLFW 在 Windows 下常需要的系统库
target_link_libraries(OpenGLDemo PRIVATE
glfw3dll
opengl32
gdi32
user32
shell32
winmm
)
# 6) 运行时需要 glfw3.dll:把它复制到 exe 同目录(否则会提示缺 DLL)
# 如果你的包里没有 bin/glfw3.dll,就把 dll 放哪儿就改哪儿
add_custom_command(TARGET OpenGLDemo POST_BUILD
COMMAND ${CMAKE_COMMAND} -E copy_if_different
"${GLFW_ROOT}/lib-mingw-w64/glfw3.dll"
"$<TARGET_FILE_DIR:OpenGLDemo>/glfw3.dll"
)加载调用方式:
//***********使用glad加载所有当前版本opengl函数
if(!gladLoadGLLoader((GLADloadproc)glfwGetProcAddress)) {
std::cout << "加载失败";
}OpenGL函数调用
OpenGl运行环境是一个巨大的状态机,每一个函数都会改变状态机的状态或者触发某个行为。下面讲几个核心函数
glViewpoint(GLint x,Glinty,GLsizei width,GLsizei height);设置窗口中实际渲染的区域,Viewport,xy是相对于窗口左下角的起始位置。相对关系如下

glClearColor(GLfloat red,GLfloat green,GLfloat blue,GLfloat alpha)';//参数就是RGBA用于设置画布清理之后的颜色,相当于配置这个默认的画布颜色。只需要配置一次。
glClear(GL_COLOR_BUFFER_BIT)执行具体的清理工作
我们每一帧,都需要把之前渲染的内容擦拭掉,然后再执行具体的绘画渲染。所以每帧都调用一下。
- 双缓冲技术。每一帧绘制任务完成后,把“背后”画布放在台前,把“台前”放在背后,这样每帧之前不会明显的割裂,可以等下一帧真的渲染好之后才显示:
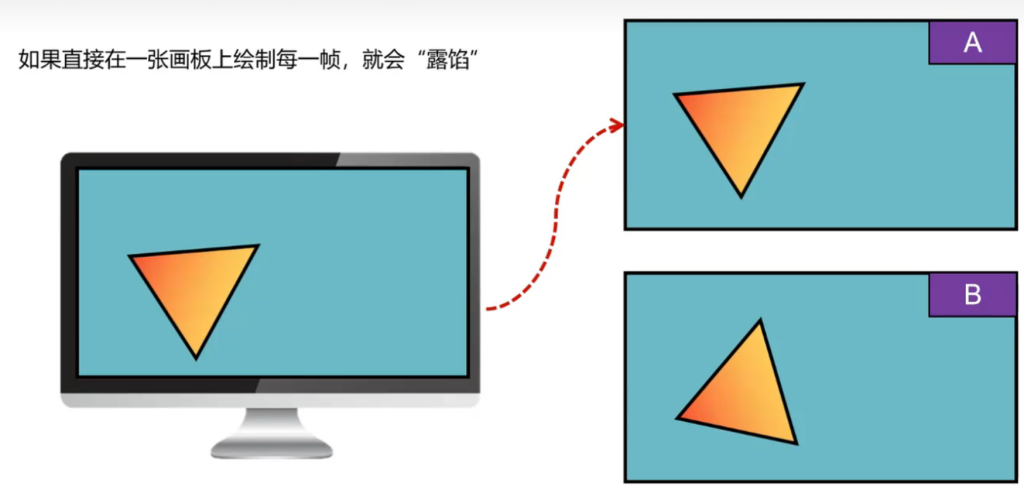
void glfwSwapBuffers(GLFWwindwow* window);用于交换前后缓冲区。每一帧交换双缓存
错误处理
opengl不会因为参数错误轻易崩溃,这也意味着错误更加的难找
GLenum errorCode = glGetError();此函数可以根据调用获取最近的一个问题的错误码。无论上面多少次都只返回最近的一个。我们可以在一个固定位置检查,然后产生错误就assert强制退出,便于我们检查
void checkError() {
GLenum errorCode = glGetError();
std::string err = "";
// 当存在错误的时候,看一下什么错误输出
if(errorCode != GL_NO_ERROR) {
switch (errorCode) {
case GL_INVALID_ENUM : err = "INVALID_ENUM"; break;
case GL_INVALID_VALUE: err = "INVALID_VALUE"; break;
case GL_INVALID_OPERATION: err = "INVALID_OPERATION"; break;
case GL_OUT_OF_MEMORY: err = "OUT_OF_MEMORY"; break;
default:
err = "UNKNOWN ERROR";
break;
}
// 存在错误输出并报错
std::cout << err << std::endl;
assert(false);
}
}当然,如果每一个函数都写还是太浪费了,我们可以继续编写CMake文件,把这个编译成库便于我们使用。
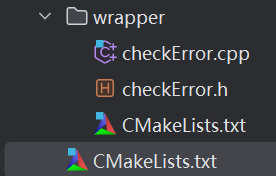
在主CMake里面,加入这个子目录
# 加入子文件夹中的次级的文件
add_subdirectory(wrapper)在子cmake里面,配置封装好
# 递归讲文件夹下所有的cpp放到WRAPPER中
file(GLOB_RECURSE WRAPPER ./ *.cpp)
# 将FUNCS中所有cpp编译为funcs这个wrapper库
add_library(wrapper ${WRAPPER})声明和实现完成后,就可以正常使用了。注意这个add_subdirectory要在定义的文件搜索路径include_directories下面,不然搜索不到include
这里,如果每次都手动引入太麻烦,那么可以借助宏,包裹一下这样便于使用。当然也可以再区分,只有debug阶段才可以使用,提高实际运行中的效率。
// 预编译宏
// 根据add_definitions(-DDEBUG)的不同同,高亮也不同;代表执行不同的宏
#ifdef DEBUG
#define GL_CALL(func) func;checkError();
#else
#define GL_CALL(func) func;
#endifApplication封装
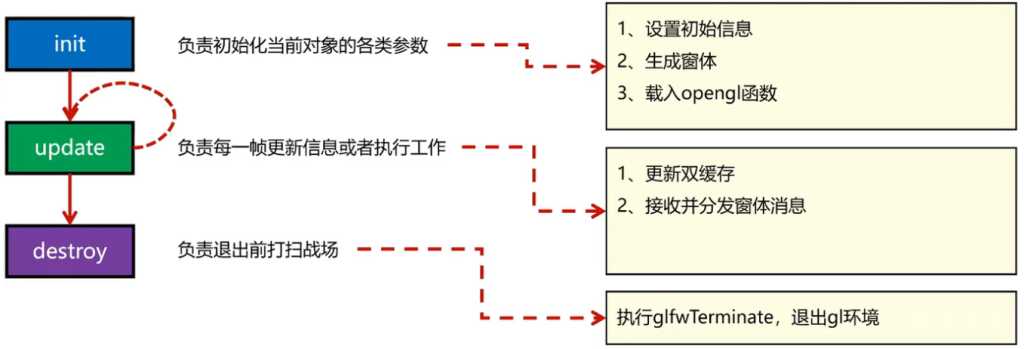
问题:opengl的绘制代码都很长,所以需要必要的封装,让代码优雅简洁。
任务:封装一个Application类,把窗体相关代码锁在里面,只暴露必要的接口
思路:每个对象都应该先初始化,之后每一帧更新或者处理数据,最后退出时候打扫战场。
一般对于窗口之类的直接单例就可以了,按照之前同样的配置好cmake
// 初始化Application的静态对象
Application* Application::mInstance = nullptr;
Application* Application::getInstance() {
// 如果已经实例化了,就直接返回
// 否则new一个出来
if(mInstance == nullptr) {
mInstance = new Application();
}
return mInstance;
}
但是这样又有问题,我的那些点击之类的处理需要怎么做呢?通过回调函数。
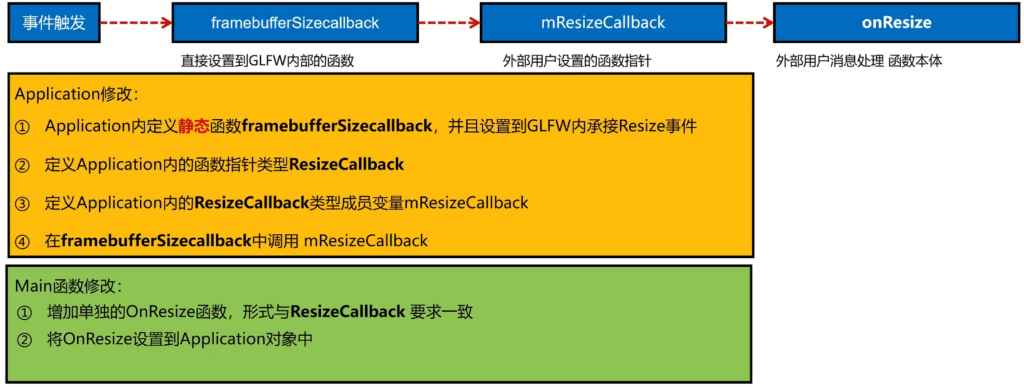
步骤具体来说:
// 1.类内定义
static void frameBufferSizeCallback(GLFWwindow* wwindow, int width, int height);
外部的实现
void Application::frameBufferSizeCallback(GLFWwindow* wwindow, int width, int height) {
std::cout << "Resize" << std::endl;
//如果存在这个函数
if(Application::getInstance()->mResizeCallback != nullptr) {
Application::getInstance()->mResizeCallback(width,height);
}
}
// 2.类外定义指针类型
using ResizeCallback = void(*)(int width,int height);
// 3.类内定义函数指针对象
ResizeCallback mResizeCallback{nullptr};
// 4.init时候初始化
glfwSetFramebufferSizeCallback(mWindow,frameBufferSizeCallback);这里,为什么frameBufferSizeCallback一定要用static呢?原理是glfwSetFramebufferSizeCallback这个glfw实现的时候,这个函数签名是
void (*)(GLFWwindow*, int, int)(普通函数指针)
而实际上,如果不加static,那么这个函数的实际类型就是
void (Application::*)(GLFWwindow*, int, int) (成员函数指针)
这个变成了一个特定类型的函数,所以不可以。且对于函数
void Application::frameBufferSizeCallback(GLFWwindow*, int, int);真实调用形式其实是:
frameBufferSizeCallback(this, window, width, height);VAO与VBO
GPU工作流程解析
图形渲染本质上,就是CPU端的C++程序控制GPU行为的过程,控制包括数据传输与指令发送。
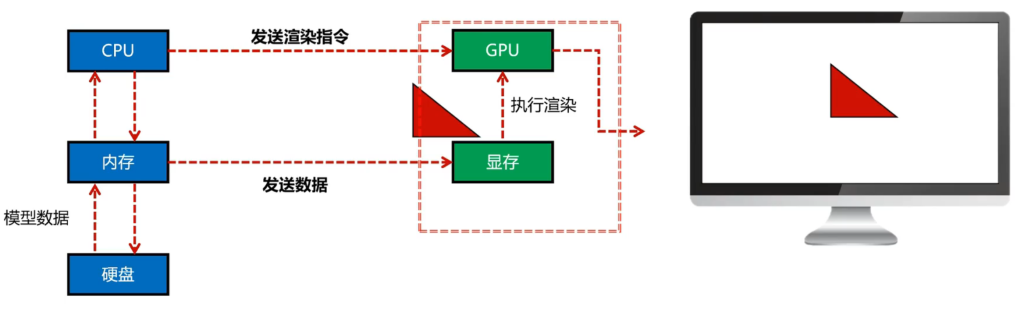
一个渲染过程包括:CPU发送指令,读取数据,于是从硬盘中读取数据,如这个三个角形加载进来。接下来,如果想要渲染,就把这个三角形数据发送到显存端,CPU再向GPU发送渲染指令,GPU再执行渲染展现效果。
注意两个点:
1.内存向显存端发送数据很花费时间
2.CPU向GPU发指令时间也很长
对于GPU,并行能力很强,内含大量的运算核心。
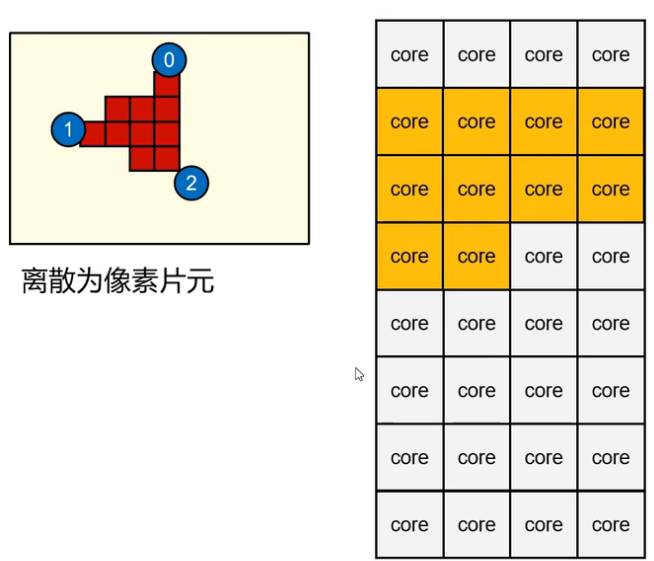
- GPU对于三角形数据的处理,可以分为两大种:顶点处理和片元处理。
- 顶点与片元的处理,统一通过着色器程序(shader)进行;是由我们自己编写在GPU端的程序
| 处理方式 | 顶点处理 | 片元处理 |
| shader类型 | VertexShader | FragmentShader |
| 具体作用 | 处理顶点,进行三维变换,屏幕投影等各种顶点的操作 | 处理像素,决定最终的像素严肃是什么 |
对于一个三角形,每个顶点运行一次共三次;对于每一个像素片元也是运行一次,共N次(取决于实际情况)。这样就称为可编程渲染管线。
NDC(标准化设备坐标)
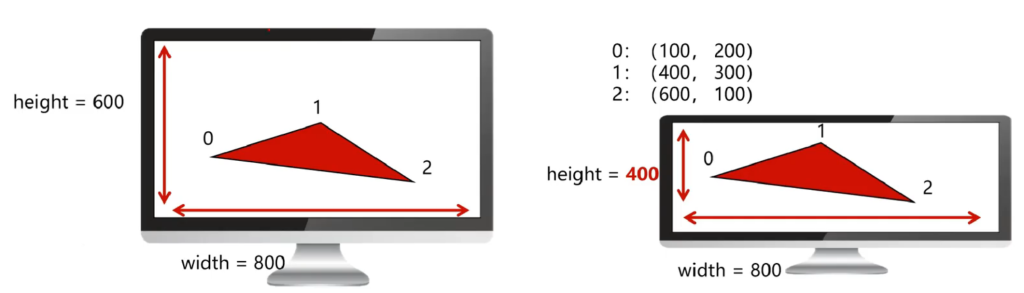
问题:不同显示设备上,如果按照同样像素大小处理不太合适。尝试用一种比例的方法处理。
解决:用-1到1之间的数字,表示顶点的坐标;本质就是比例。
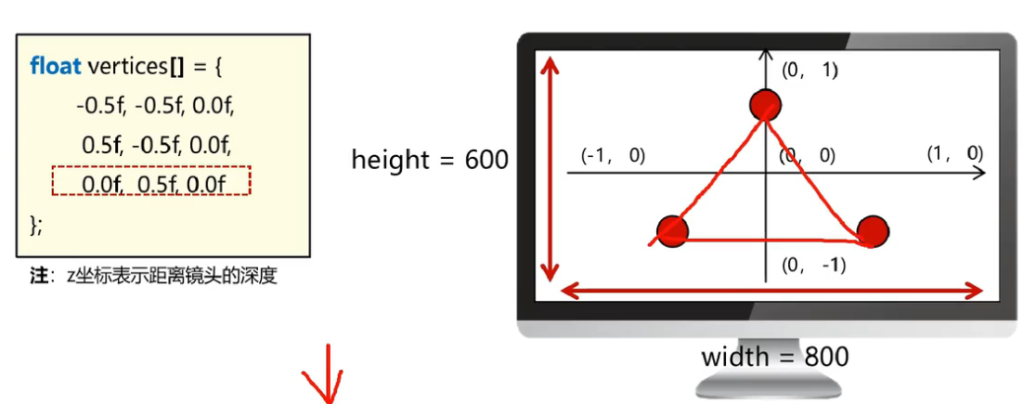
那我们可以通过NDC的方式绘制一个标准的三角形,在不同屏幕上都可以完整展示,只是比例不同。
VBO
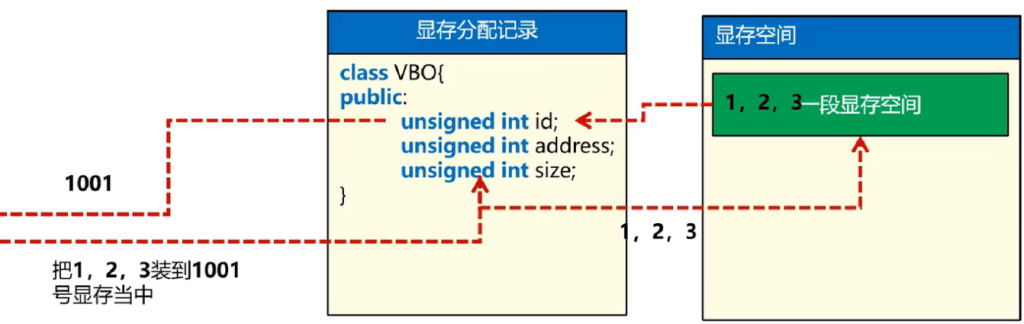
VBO:顶点缓存对象,标示量在GPU显存上一段存储数据空间。是一个标识的对象。
VBO的创建
void glGenBuffers(GLsizei n,GLuint *buffers);- n:创建多少个vbo
- buffers:创建出来的vbo编号们,都放在buffer指向的数组中
案例:
// 创建一个对象,编号存在vbo里面,没有分配真正的显存!
GLuint vbo = 0;
glGenBuffers(1,&vbo);
// 创建多个对象,放在buffer数组中,没有分配真正的显存!
GLuint vboArr[] = {0,0,0};
glGenBuffers(3,vboArr);VBO的销毁
void glDeleteBuffersglGenBuffers(GLsizei n,GLuint *buffers);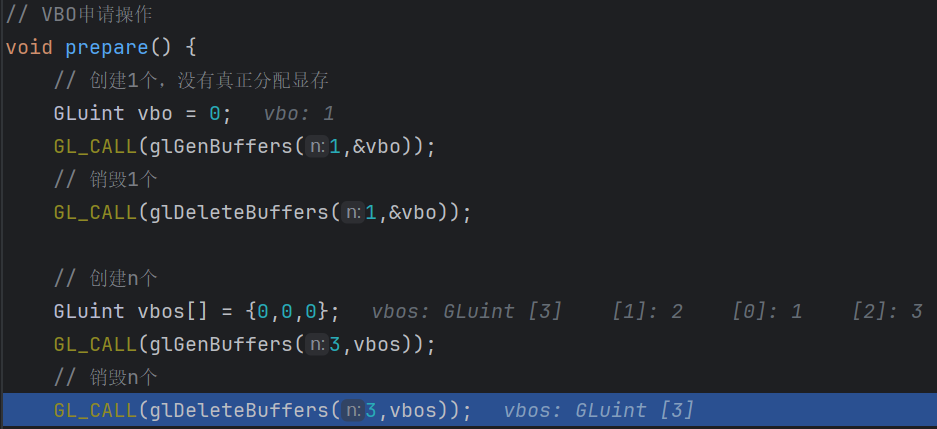
可以看到VBO按照顺序生成
VBO的绑定与数据传输
绑定:把某个资源与opengl状态机种某一个状态关联
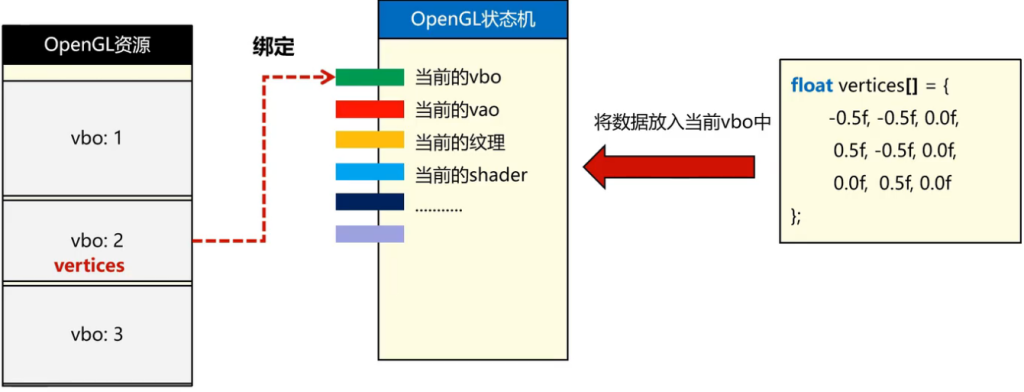
这里比如说,我就是要对当前vbo操作,那么我切换不同vbo操作的当前那一些东西就不太一样。
void prepare() {
float vertices[] = {
-0.5f,-0.5f,0.0f,
0.5f,-0.5f,0.0f,
0.0f,0.5f,0.0f
};
// 生成一个VBO
GLuint vbo = 0;
GL_CALL(glGenBuffers(1,&vbo));
// 绑定当前vbo到当前opengl状态机的当前vbo插槽上
// target:GL_ARRAY_BUFFER当前vbo的插槽
// buffer:vbo绑定的插槽编号
GL_CALL(glBindBuffer(GL_ARRAY_BUFFER,vbo));
// 向当前vbo传输数据,开辟显存
// target:GL_ARRAY_BUFFER当前vbo的插槽
// size:传输进去的大小
// data:装有数据的数组指针
// usage:
// GL_STATIC_DRAW:vbo模型数据不会频繁改变
// GL_DYNAMIC_DRAW:vbo模型数据会频繁的改变
GL_CALL(glBufferData(GL_ARRAY_BUFFER,sizeof(vertices),vertices,GL_STATIC_DRAW));
}VBO多属性数据
实际上要存取的数据属性很多,怎么办呢?
-SingleBuffer:每一个属性放在一个单独的vbo当中
-InterleavedBuffer:数据是交叉的,存储在一个vbo里面。就是继续拼接在后面,本质还是一样的描述

void prepareSingleBuffer() {
// 1.准备定点位置数据与颜色数据
float positions[] = {
-0.5f,-0.5f,0.0f,
0.5f,-0.5f,0.0f,
0.0f,0.5f,0.0f
};
float colors[] = {
1.0f,0.0f,0.0f,
0.0f,1.0f,0.0f,
0.0f,0.0f,1.0f
};
// 2.为位置&颜色数据各自生成一个vbo
GLuint posVbo = 0,colorVbo = 0;
GL_CALL(glGenBuffers(1,&posVbo));
GL_CALL(glGenBuffers(1,&colorVbo));
// 3.给两个分开的vbo各自填充数据
// 先填充position的vbo
GL_CALL(glBindBuffer(GL_ARRAY_BUFFER,posVbo));
GL_CALL(glBufferData(GL_ARRAY_BUFFER,sizeof(positions),positions,GL_STATIC_DRAW));
// 再填充color的数据
GL_CALL(glBindBuffer(GL_ARRAY_BUFFER,colorVbo));
GL_CALL(glBufferData(GL_ARRAY_BUFFER,sizeof(colors),colors,GL_STATIC_DRAW));
}VAO
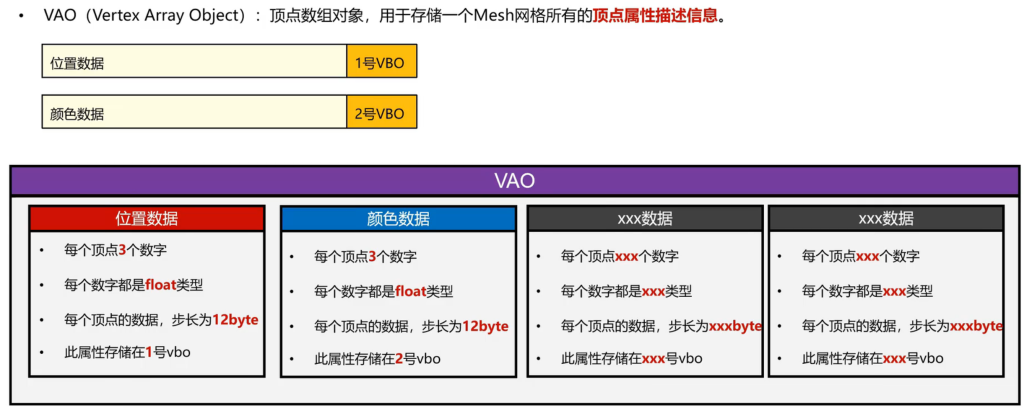
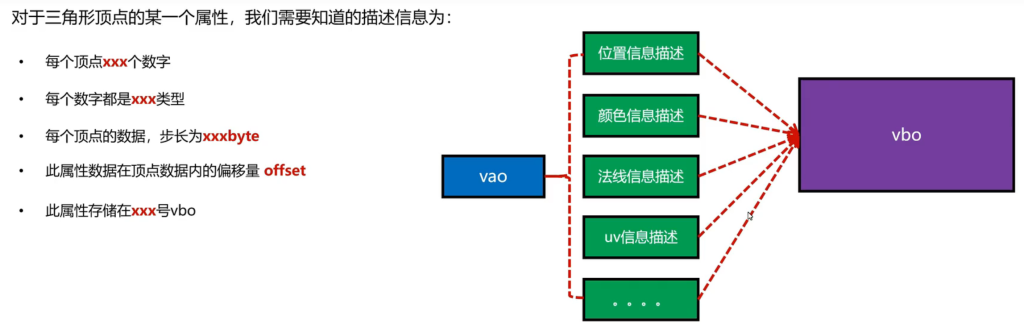
对于刚才的数据,存入GPU之后,无法对应到具体的用途,需要有方法去描述它。
有三个描述,分别是size,type和stride

如果同时有位置和颜色属性,之前有提到可以用两个VBO存储,那么就再加一个指定。

那么VAO是什么?把前面那个mesh的描述信息全部集合起来得到我们的VAO
当然我们还有一种写法,就是都放在一起的,那么解决方案就是可以再加一个偏移。
//VAO创建
void glGenVertexArray(GLsizei n ,GLuint *arrays)- n:创建多少个vao
- arrays:创建出来的vao编号门,都放在arrays指向的数组中
//VAO删除
void glDeleteVertexArrays(GLsizei,GLuint *arrays)- n:删除多少个vao
- arrays:要删除的vao存放的数组
// VAO的绑定
void glBindVertexArray(GLunint array)- array:要绑定的vao编号
// VAO加入描述属性
void gIVertexAttribPointer(GLuint index, GLint size, GLenum type, GLboolean normalized,GLsizei stride, const void *pointer)- index:要描述第几个属性
- size:这个属性包含几个数字
- type:这个属性每个数字是什么数据类型
- normalized:是否归一化(暂时不用)
- stride:每个顶点数据vbo的步长
- pointer:这个属性在每个顶点数据内的偏移量
具体实现
void prepareSingleBuffer() {
// 1.准备定点位置数据与颜色数据
float positions[] = {
-0.5f,-0.5f,0.0f,
0.5f,-0.5f,0.0f,
0.0f,0.5f,0.0f
};
float colors[] = {
1.0f,0.0f,0.0f,
0.0f,1.0f,0.0f,
0.0f,0.0f,1.0f
};
// 2.为位置&颜色数据各自生成一个vbo
GLuint posVbo = 0,colorVbo = 0;
GL_CALL(glGenBuffers(1,&posVbo));
GL_CALL(glGenBuffers(1,&colorVbo));
// 3.给两个分开的vbo各自填充数据
// 先填充position的vbo
GL_CALL(glBindBuffer(GL_ARRAY_BUFFER,posVbo));
GL_CALL(glBufferData(GL_ARRAY_BUFFER,sizeof(positions),positions,GL_STATIC_DRAW));
// 再填充color的数据
GL_CALL(glBindBuffer(GL_ARRAY_BUFFER,colorVbo));
GL_CALL(glBufferData(GL_ARRAY_BUFFER,sizeof(colors),colors,GL_STATIC_DRAW));
// 生成vao并绑定
GLuint vao = 0;
glGenVertexArrays(1,&vao);
glBindVertexArray(vao);
// 4.分别将位置/颜色属性描述信息加入vao中
// 4.1描述位置属性
glBindBuffer(GL_ARRAY_BUFFER,posVbo);//只有绑定了posVbo,下面的属性才会与此vbo相关
glEnableVertexAttribArray(0);
glVertexAttribPointer(0,3,GL_FLOAT,GL_FALSE,3 * sizeof(float),(void*)0);
// 4.2描述颜色属性
glBindBuffer(GL_ARRAY_BUFFER,colorVbo);
glEnableVertexAttribArray(1);
glVertexAttribPointer(1,3,GL_FLOAT,GL_FALSE,3 * sizeof(float),(void*)0);
// 清空一下绑定
glBindVertexArray(0);
}
void prepareInterleavedBuffer() {
// 准备顶点数据和颜色
float vertices[] = {
-0.5f,-0.5f, 0.0f, 1.0f, 0.0f, 0.0f,
0.5f, -0.5f, 0.0f, 0.0f, 1.0f, 0.0f,
0.0f, 0.5f, 0.0f, 0.0f, 0.0f, 1.0f
};
// 生成一个vbo
GLuint vbo = 0;
glGenBuffers(1,&vbo);
// 确定操作这个buffer,然后绑定数据注入
glBindBuffer(GL_ARRAY_BUFFER,vbo);//确定操作这个
glBufferData(GL_ARRAY_BUFFER,sizeof(vertices),vertices,GL_STATIC_DRAW);
//vao
GLuint vao = 0;
glGenVertexArrays(1,&vao);
glBindVertexArray(vao);
// 把整个信息存进去
// 位置描述信息
glBindBuffer(GL_ARRAY_BUFFER,vbo);
glEnableVertexAttribArray(0);
glVertexAttribPointer(0,3,GL_FLOAT,GL_FALSE,6*sizeof(float),(void*)0);
// 颜色描述信息
glEnableVertexAttribArray(1);
glVertexAttribPointer(1,3,GL_FLOAT,GL_FALSE,6*sizeof(float),(void*)(3*sizeof(float)));
// 解绑当前vao
glBindVertexArray(0);
}绘制流程
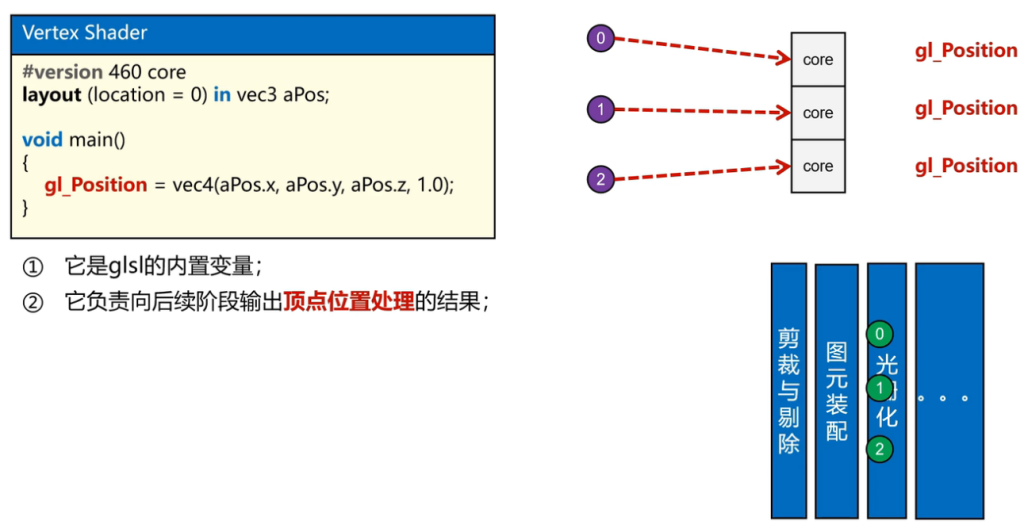
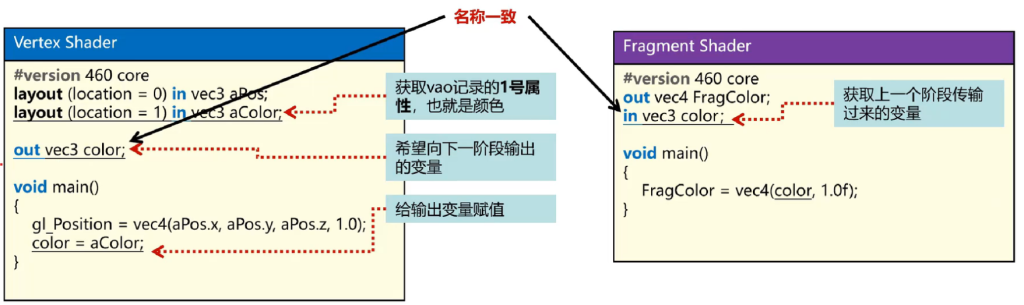
Shader:一种运行在GPU端,类C语言,用于处理顶点数据及决定像素最终片元最终着色
对于左侧的,用于顶点处理,因此叫做VertesShader;右侧的,处理最终的片元颜色,叫做FragmentShader
GLSL语言(Graphic Library Shader Language)
着色器是使用一种叫做GLSL的类C语言写成的。是为图形计算量身定制的,包含一些对向量矩阵的特性。
- 特点:
- 本身是一种把输入转化为输出的程序
- 是一种非常独立的程序,彼此之间无法通信,只能够通过输入输出之间相互承接
layout函数
- layout(location=n) 告诉vertexShader去vao的第n个描述属性中取出数据,aPo韦变量名

gl_position函数,根据读取的数据最终转化为最终的NDC坐标。
对于FragmentShader,
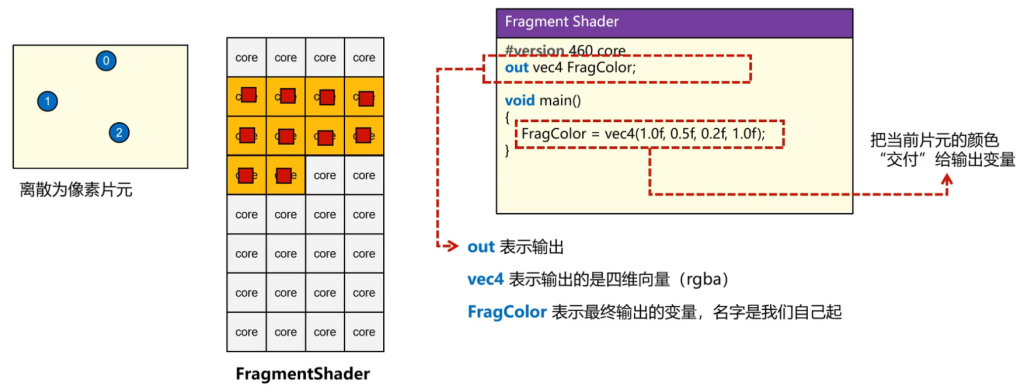
是一个out类型变量,意味着最后需要输出
shader的编译
- Shader作为GPU端运行的程序,也需要被编译+链接成为一款可运行的程序

- count:字符串数组的个数
- string:字符串数组
- length:每一个字符串数组长度
绘制流程梳理
- 我们已经准备好了几何数据与材质程序

- 接下来告诉GPU,使用我们的集合程序与材质程序,来进行绘制
void glUseProgram(GLuint program)- 设置接下来绘制的时候,所使用的Shader程序
void glBingVertexArray(GLuint array)- 设置接下来绘制的时候,所使用的VAO几何信息
void glDrawArrays(GLenum mode,GLint first,GLsizei count)- 向GPU端发出渲染指令(DrawCall)
- 降低DrawCall就是降低向GPU发出渲染指令的次数
- mode:绘制模式(GL_TRIANGLES,GL_LINES)
- first:从第几个顶点开始绘制
- count:绘制到第几个顶点数据

不同的first和count对应选取最终不同的点。注意来说,画三角形和画直线需要满足最少要求的点。
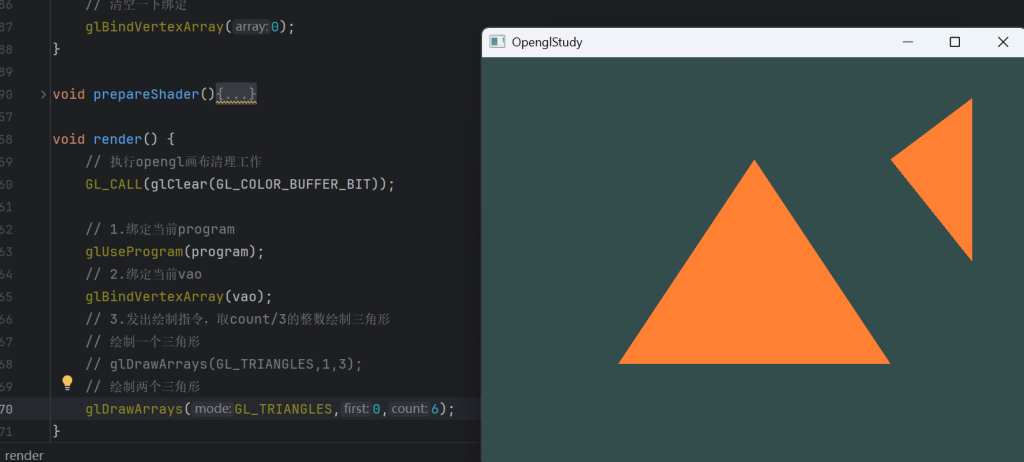
void render() {
// 执行opengl画布清理工作
GL_CALL(glClear(GL_COLOR_BUFFER_BIT));
// 1.绑定当前program
glUseProgram(program);
// 2.绑定当前vao
glBindVertexArray(vao);
// 3.发出绘制指令
glDrawArrays(GL_TRIANGLES,0,3);
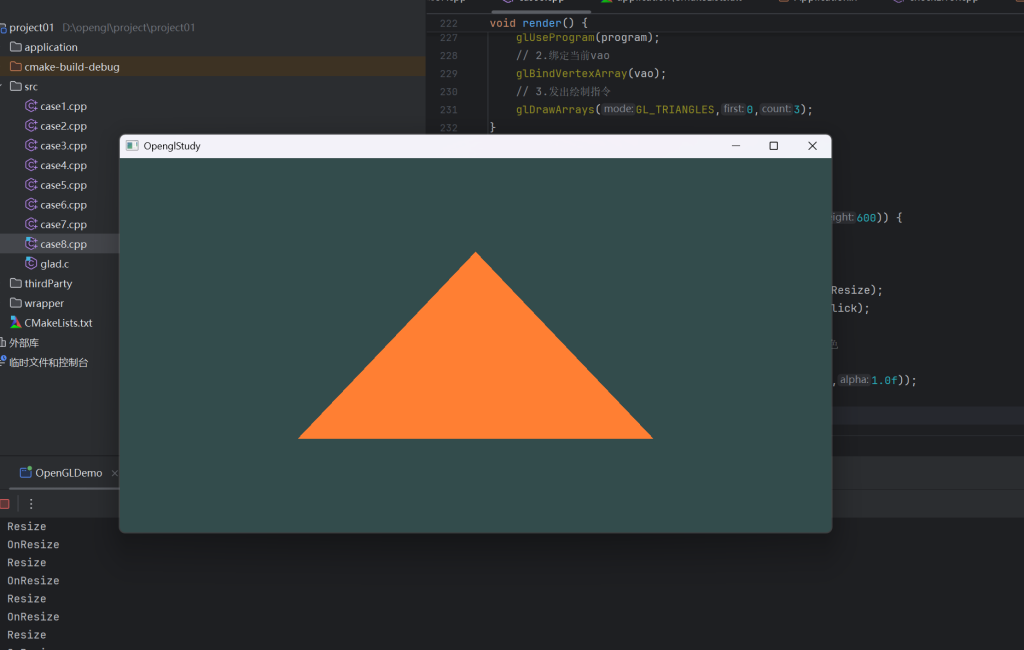
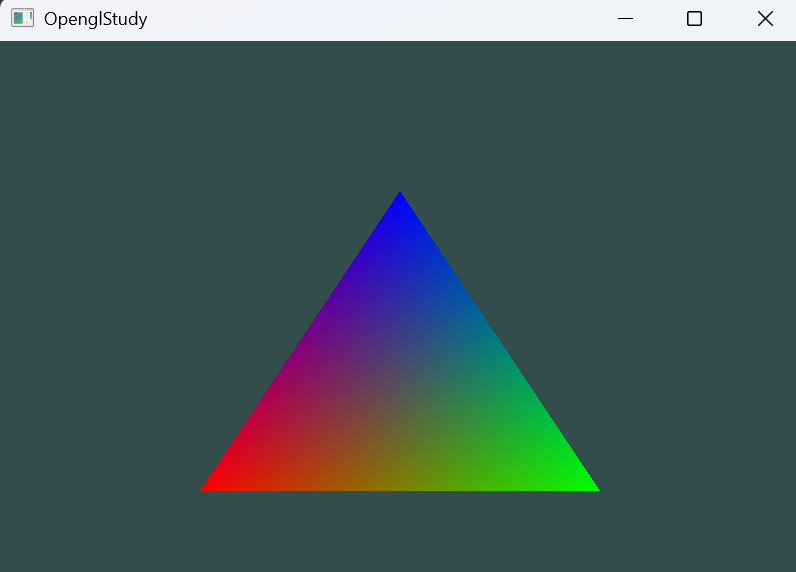
}绘制,记得提升一下变量为全局(便于测试),然后终于出现了第一个三角形 sobsobsob
绘制多顶点
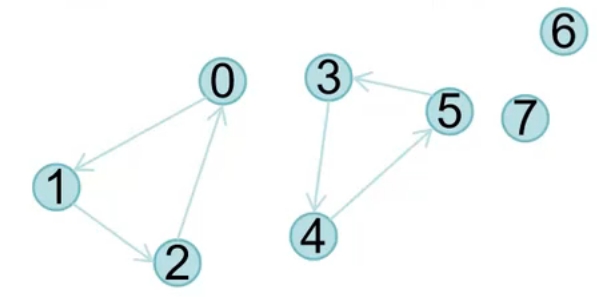
刚才有提到从哪一个顶点开始,如果变换不同的结果会怎么样呢?如果first是1,就绘制0-1-2三角形,如果first是1,那就绘制1-2-3三角形
绘制模式
void glDrawArrays(GLenum mode,GLint first,GLsizei count)- mode:决定了对于输入的几何顶点,如何相连成为三角形或者直线
GL_TRIANGLES:每三个顶点构成一个三角形,不足三个则忽略
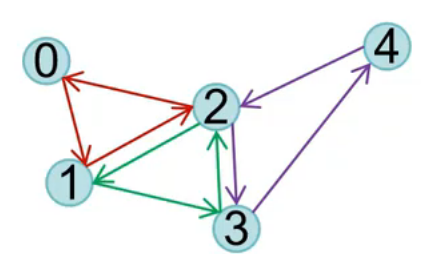
GL_TRIANGLE_STRIP:保证在不重叠情况下,三角形旋转方向一致
如果末尾点序列n为偶数,则链接规则为[n-2,n-1,n]
如果末尾点序列n为奇数,则链接规则为[n-1,n-2,n]
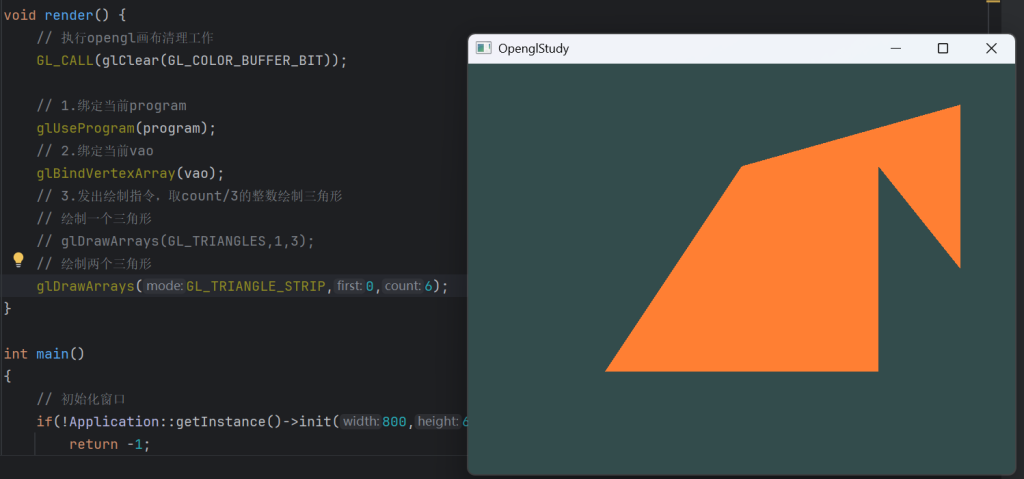
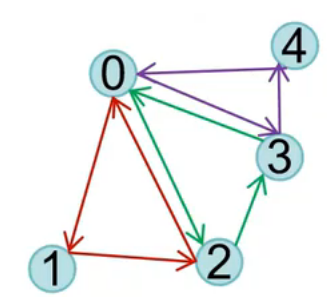
GL_TRIANGLE_FAN:绘制为扇形序列,以v0为起点
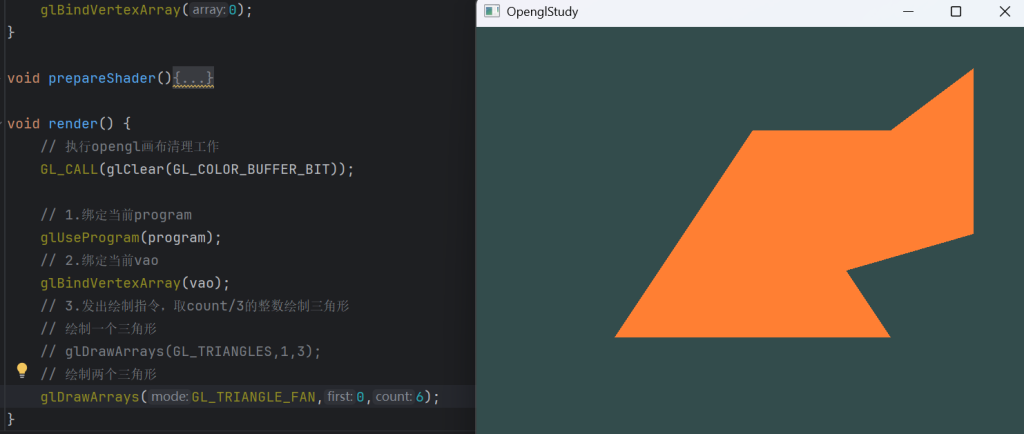
GL_LINES:每两个顶点构成一条直线
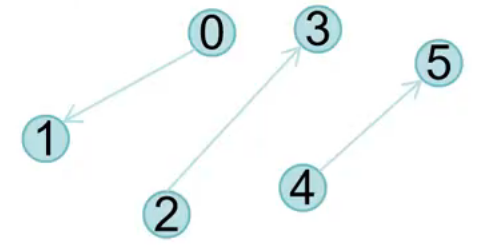
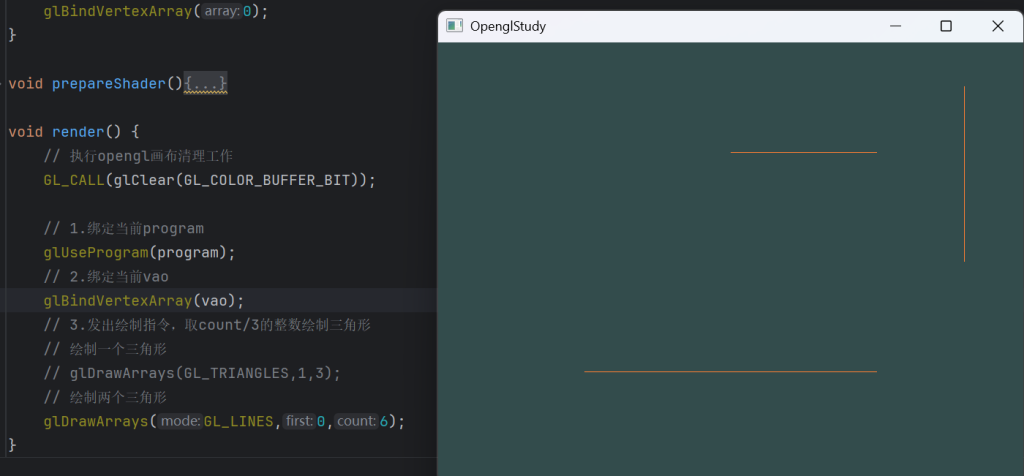
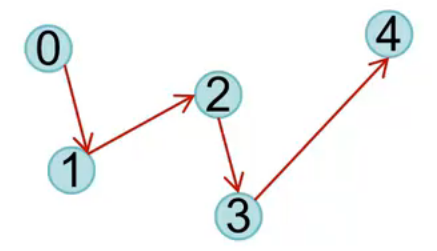
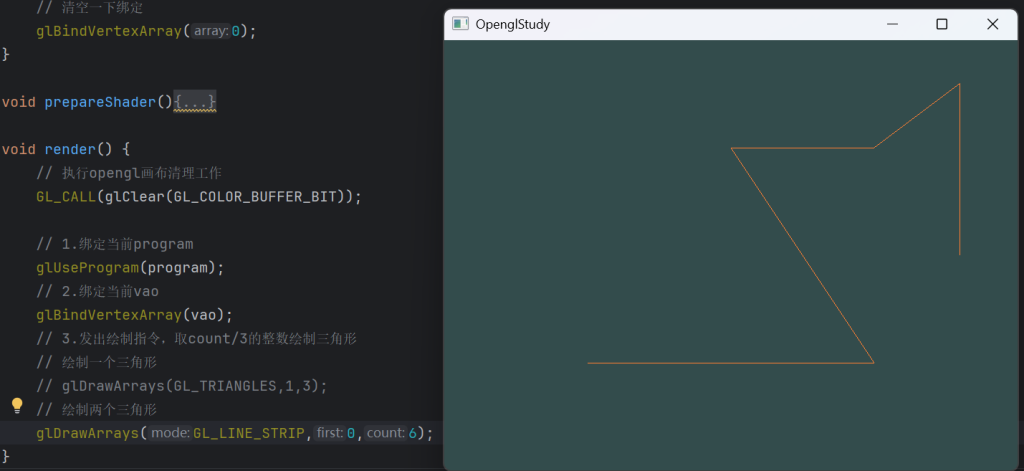
GL_LINE_STRIP:顺序不断链接
EBO
问题:对于绘制三角形使用Strip和Fan太死板,不常用。且没有办法复用顶点,比如想用023怎么办呢?
顶点索引:用于描述一个三角形使用哪几个顶点数字的序列
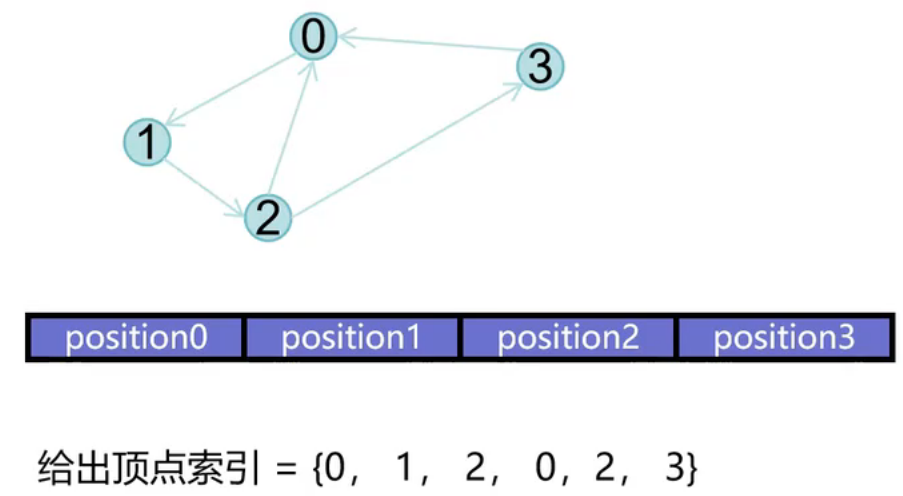
EBO(Element Buffer Object):用于存储顶点绘制顺序索引的GPU显存区域

整体流程和之前的VAO绑定流程类似
EBO绘制流程
void glDrawElements(GLenum mode,GLsizei count,GLenum type ,const void *indices)- mode:绘制模式
- count:使用ebo中多少个数字来绘制
- type:索引的数据类型
- indices:
- 如果使用了ebo,通常填写0
- 如果使用了ebo,其不填写0,表示索引内偏移
- 如果不适用ebo,可以直接传入索引数组(效率低,相当于每次再从cpu发)
彩色三角形绘制和差值算法
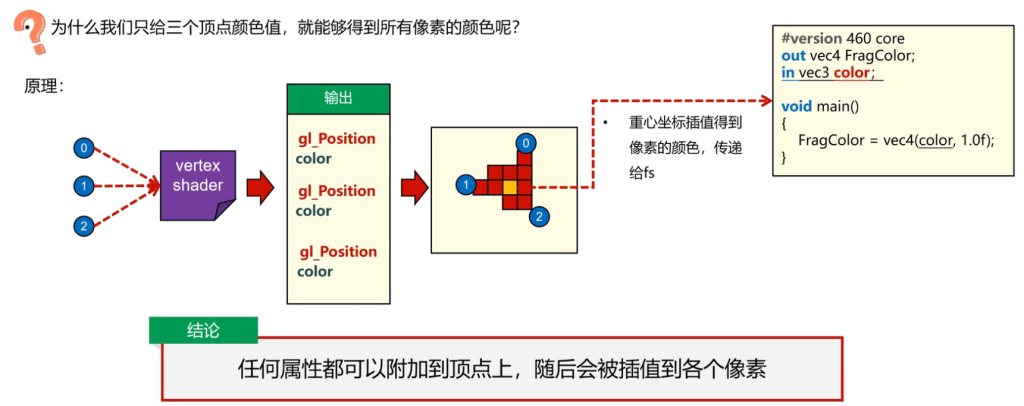
插值算法
线性插值算法:两个点时候,按照线段长度比例分配
重心插值算法:三个点时候,按照顶点相对三角形面积分配比例。
且任何属性其实都可以这样插值,传递给fragmentShader时候已经插值完了
Shader
文件用glsl结尾
因为我们还是需要编译之类的,因此我们创建一个文件夹处理这些。具体的shader文件也配置相关的内容
按照同样的,写好CMake文件夹,然后把相关内容都进行封装
GLSL
着色器是使用一种叫做GLSL的类C语言写成的。是为图形计算量身定制的,包含一些对向量矩阵的特性。
- 特点:
- 本身是一种把输入转化为输出的程序
- 是一种非常独立的程序,彼此之间无法通信,只能够通过输入输出之间相互承接
基础数据类型和C类型类似,向量数据类型
| 类型 | 描述 |
| vecn | 包含n个float分量的向量 |
| bvecn | 包含n个bool分量的向量 |
| ivecn | 包含n个int分量的向量 |
| uvecn | 包含n个unsigned int分量的向量 |
| dvecn | 包含n个double分量的向量 |
向量使用方式比较灵活
一、向量初始化(Vector Initialization)
//显式初始化
vec3 color0 = vec3(1.0, 0.0, 0.0);
//分别指定每个分量的值(x, y, z 或 r, g, b)
//统一初始化
vec3 color1 = vec3(1.0);
// 等价于vec3(1.0, 1.0, 1.0);二、向量分量访问(xyzw / rgba)
GLSL 中向量支持多套语义访问方式:
- 空间坐标:
x y z w - 颜色分量:
r g b a
vec4 color = vec4(0.8, 0.0, 0.0, 1.0);
float x = color.x; // 0.8
float r = color.r; // 0.8
float w = color.w; // 1.0
float a = color.a; // 1.0x ≡ r,w ≡ a,只是语义不同,用来指代特定的位置
三、向量重组(Swizzling)
Swizzling 可以任意重排、复制向量分量,非常灵活。
vec4 color = vec4(0.8, 0.7, 0.6, 1.0);
vec4 param0 = color.xyzz; // (0.8, 0.7, 0.6, 0.6)
vec4 param1 = color.zyzz; // (0.6, 0.7, 0.6, 0.6)
vec4 param2 = param0.xxxx + param1.yzwx;四、构造更灵活的向量(混合使用)
可以把 已有向量分量 + 常量 组合成新向量:
vec4 color = vec4(0.8, 0.7, 0.6, 1.0);
vec4 param0 = vec4(color.xyz, 0.5);// (0.8, 0.7, 0.6, 0.5)
vec4 param1 = vec4(color.yz, 0.5, 0.9);// (0.7, 0.6, 0.5, 0.9)变量分类
输入变量:vs和fs都可以承接上一个步骤的计算结果或者属性输入
Vs输入
layout(location = 0 )in vec3 aPos;
Fs输入
in vec3 color;输出变量:
vs和fs都可以向下一个渲染管线步骤输出变量
vs向后输出变量,进过插值到达fs中
输出
out vec3 param;
...
param = vec3(1.0);Uniform变量:
负责CPU与Shader之间直接的变量传递
输入变量
在vs中的输入变量,成为属性变量,是通过vao的描述,从vbo中读取顶点属性
layout(location=0) in vec3 aPos;但其实,也可以不用location,不用显示的layout来获取,即:
in vec3 aPos;那怎么做呢,其实就可以在vbo绑定vao的时候,就把这个描述id获取了,然后绑定
glVertexAttribPointer(0,3,GL_FLOAT,GL_FALSE,sizeof(float) * 3,(void*)0);这个0就是我们自己配置的,我们这时候从我们program里面获取
GLunint posLocation = glGetAttribLocation(shader->mProgram,"aPos");
...
glEnableVertexAttribArray(posLocation);
glVertexAttribPointer(posLocation,3,GL_FLOAT,GL_FALSE,sizeof(float) * 3,(void*)0);Uniform
- 在Shader执行运算的时候,彼此之间数据不共享,但是指令一致
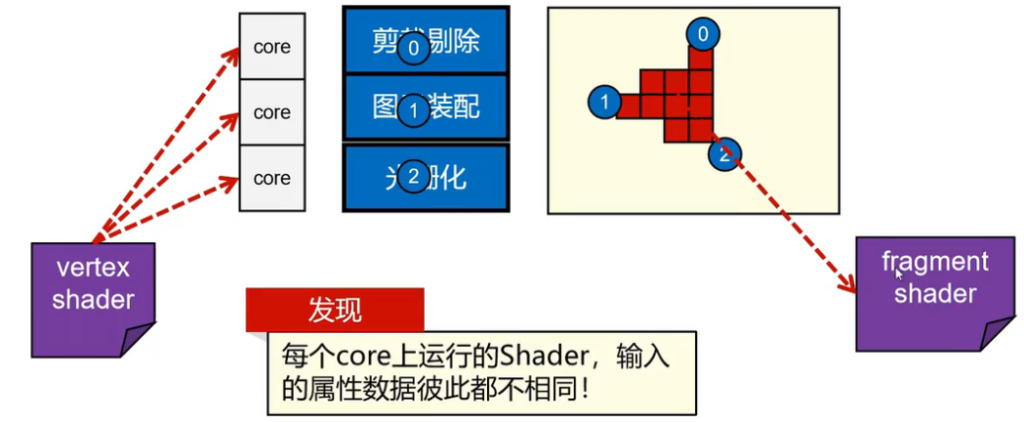
问题:所有的vs计算需要同一个数据,所有的fs计算需要同一个数据怎么办?
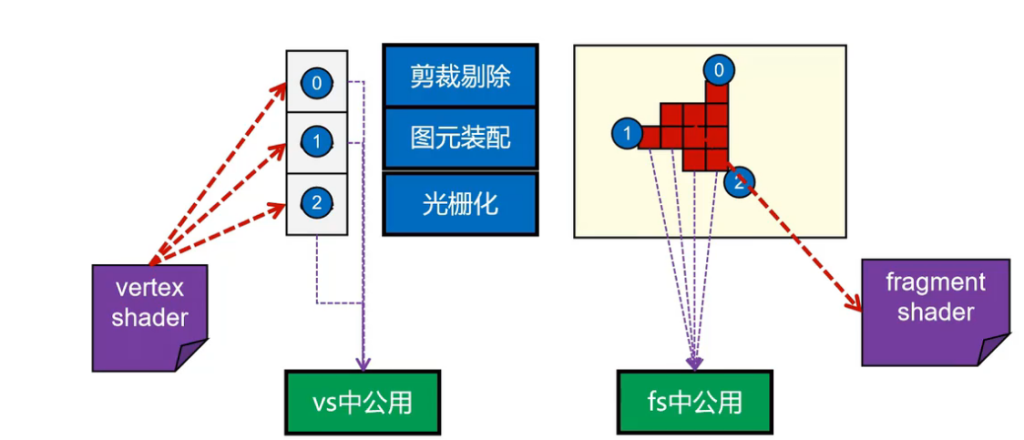
被当前Shader运行的所有运算单元共享的变量,成为Uniform变量。
| 类型 | 数据份数 | 是否共享 | 含义 |
|---|---|---|---|
uniform | 1 份 | ✅ 所有 core 共享 | 全局参数 |
attribute / in | 顶点/片元个数份 | ❌ 不共享 | 每个顶点/片元不同 |
Attribute:顶点位置,受力
Uniform:系统时间,Mesh的ID号,光照方向
语法
- 在GLSL中,使用uniform关键字来定义Uniform变量
uniform vec3 direction;
uniform float time;
void main()
{
direction = direction * 2.0;
time = time + 1.0f;
}- 设置Shader当中的Uniform变量
// 获取uniform变量在shader中的位置编号
GLint location = glGetUniformLocation(program,"time");
// 为location对应的uniform变量设置值
glUniform1f(location,0.5f); //专门更新一个float组成的变量
// 获取uniform变量在shader中的位置编号
GLint location1 = glGetUniformLocation(program,"direction");
glUniform3f(location,0.5f,1.0f,0.8f);//专门更新三个float组成的变量- 命名规则
glUniform+{1|2|3|4} + {f|i|ui}
示例1
借助Uniform实现三角形忽明忽暗?
怎么做呢?原理是让颜色随着时间周期性变化,那么来看,套用时间的正弦函数就可以了,把时间设置为uniform,然后配置随着时间更改。如果vs和fs都配置了,那么最终只有一个同名变量
#vertex.glsl或vertex.glsl里面都行 反正都可以找出来。因为都已经编成program了
color = aColor * (sin(time) + 1.0f) / 2.0f;
#main.cpp
shader->setFloat("time",glfwGetTime());实现左右移动,提高速度可以改变周期变快。
gl_Position = vec4(aPos.x + sin(time),aPos.y,aPos.z,1.0);
纹理与采样
把图片贴到三角形上显示的过程,即纹理贴图的过程

UV
图片和展示框大小不一样,需要调整。怎么办呢?
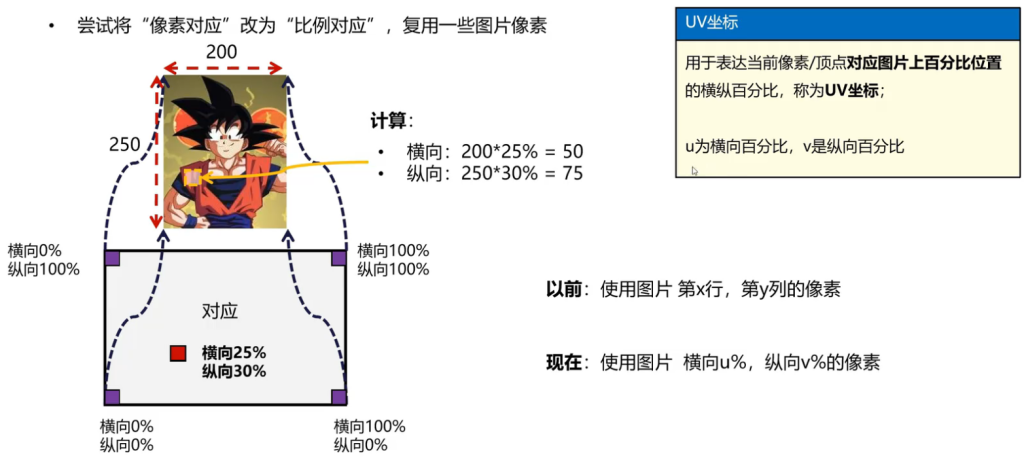
所以,这个UV坐标其实就是横向和纵向的百分比。我们通常在三角形的顶点上规定uv坐标的具体数值作为具体顶点属性,然后通过插值算法达到每一个片元像素。
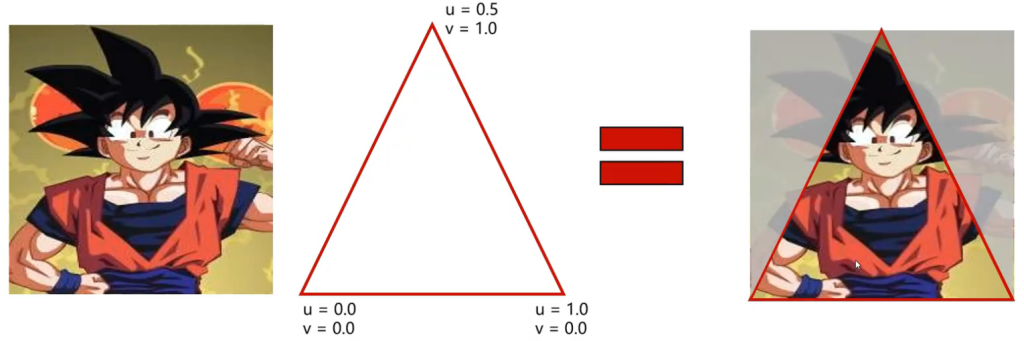
纹理与采样
- 纹理对象(Texture):在GPU端用来以一定形式存放纹理图片描述信息与数据信息的对象。
- 采样器(Sampler):在GPU端,用来根据uv坐标以一定算法从纹理中获取颜色的过程称为采样,执行采样的对象称为采样器
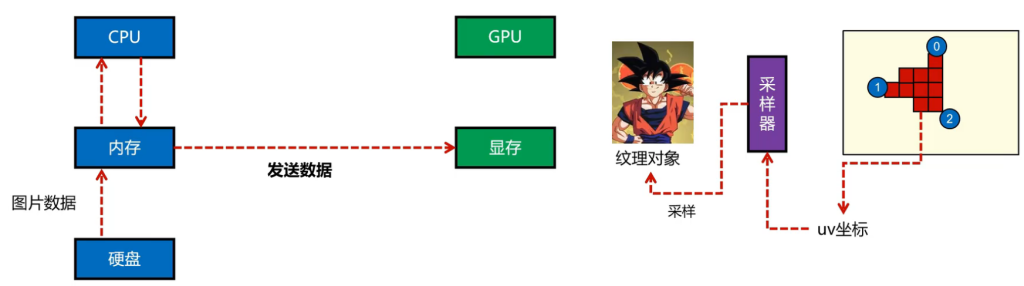
对于硬盘中的数据,CPU发送指令读取,读取后读到内存中,接着发送到显存中。根据最终绘制图案光栅化的结果,对于中间每一个点都有uv坐标的插值,把这个交给采样器,从纹理对象中获得最终的采样。
读取与纹理API
使用stblmage库(只需要头文件),读取图片。
stbi_uc *stbi_load(char const *filename, int *x, int *y, int *comp, int req_comp)- filename:相对文件路径
- xy:图片的长度跟宽度,内部会直接读取出来
- comp:读入图片的本身的通道种类(RGB\RGBA\GREY)
- req_comp:期望读出来的数据格式(RGB\RGBA\GREY)
在读取图片上,图片像素往往按照左上方为(0,0)组织数据,而Oplengl按照左下方为(0,0),因此必须要翻转y轴才可以,即需要调用:
stbi_set_flip_vertically_on_load(true);创建纹理对象
void glGenTextures(GLsizei n ,GLuint *textures);- n:创建多少个纹理对象
- textures:创建出的纹理对象编号数组
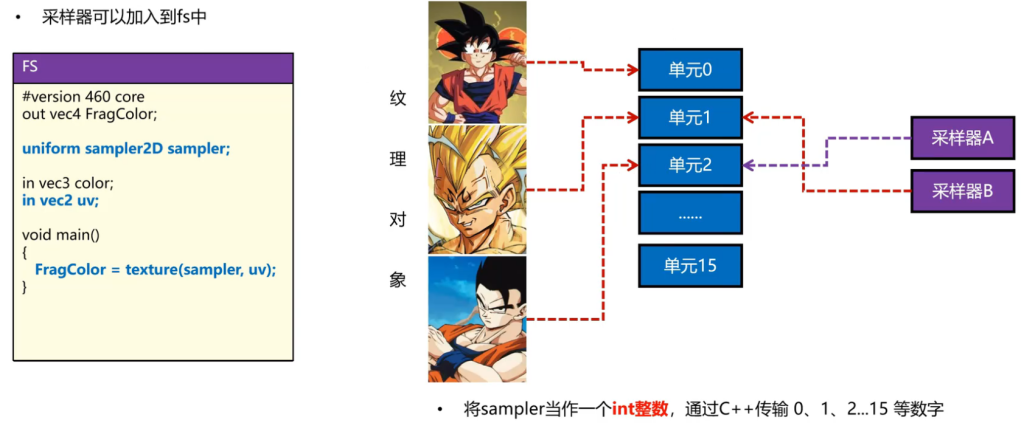
纹理单元(Texture Units)
纹理单元,用于链接才样子与纹理对象,让Sampler找到去哪个纹理对象采样
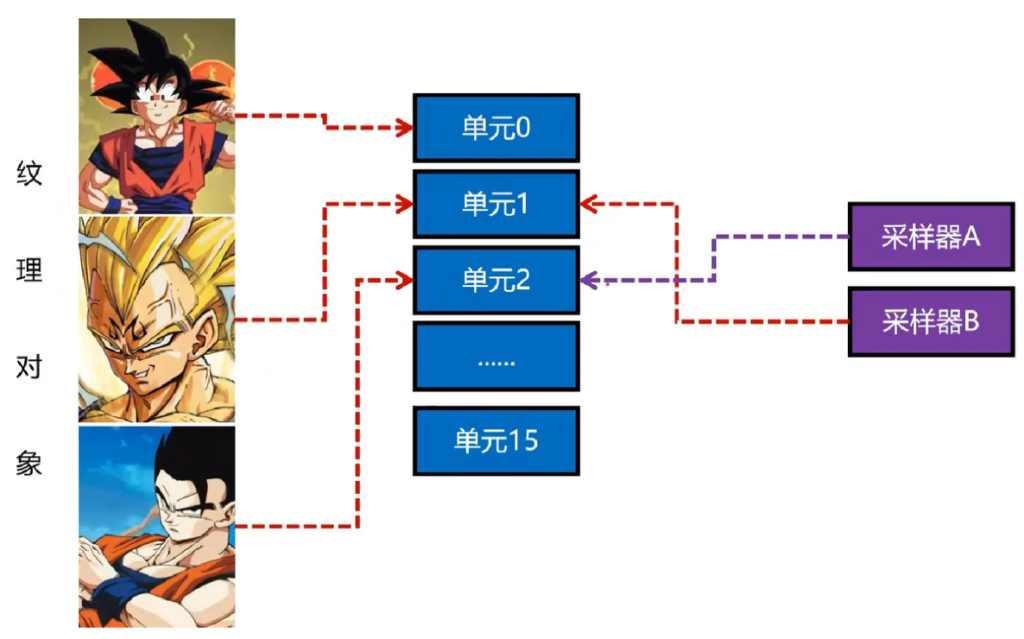
激活纹理单元
void glActiveTexture(GLenum textureUnit)- textureUnit:激活哪一个纹理单元
绑定纹理对象
void glBindTexture(GLenum target, GLenum texture)- target:将纹理绑定到GL状态机的哪个插槽
- texture:绑定此纹理编号对应纹理对象
注意:先激活某个纹理单元,再绑定某个纹理对象,可以将对象与单元链接
创建纹理对象
开辟显存,传输数据
void glTexlmage2D(
GLenum target,
GLint level,
GLint internalformat,
GLsizei width, GLsizei height,
GLint border,
GLenum format,
GLenum type,
const void *pixels)- target:给GL状态机的那个纹理插槽传输数据
- level:给mipmap哪个层级传输数据
- internalformat:希望纹理对象中图片像素格式
- width,height:最终宽高
- border:历史遗留,总是0
- format:原始图片格式
- type:单通道数据格式
- pixels:数据数组指针
代码
void prepareTexture() {
// stbImage 读取图片
int width, height,channels;
//-- 翻转y轴
stbi_set_flip_vertically_on_load(true);
// 读取数据,channels是读入图片的本身的通道种类(RGB\RGBA\GREY),STBI_rgb_alpha是期望读出来的类型
unsigned char* data = stbi_load("assets/textures/back.png",&width,&height,&channels,STBI_rgb_alpha);
// 生成纹理并激活单元绑定
glGenTextures(1,&texture);
// --激活纹理单元
glActiveTexture(GL_TEXTURE0);
// --绑定纹理对象
glBindTexture(GL_TEXTURE_2D,texture);
// 传输纹理数据,开辟显存
glTexImage2D(GL_TEXTURE_2D,0,GL_RGBA,width,height,0,GL_RGBA,GL_UNSIGNED_BYTE,data);
// 释放数据
stbi_image_free(data);
}纹理过滤方式
两种情况
采样像素>图片像素
- 临近像素(nearest):根据uv坐标计算出来取最近的整数
- 问题:可能导致
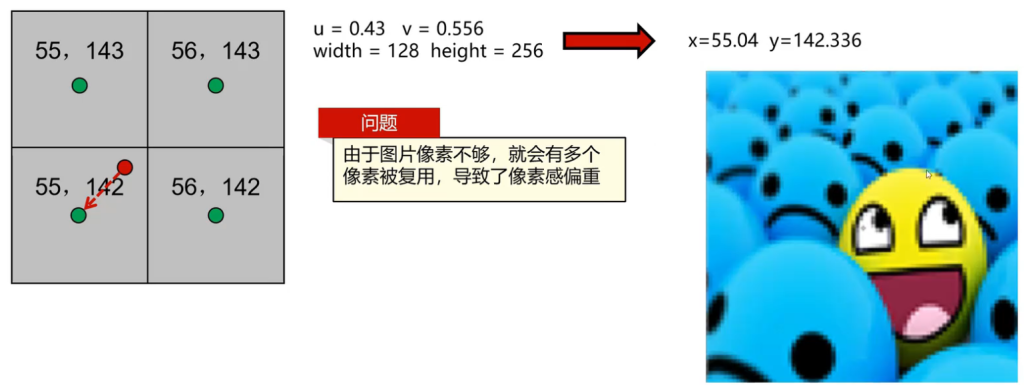
双线性插值(linear):结合最近的几个像素得到新像素的颜色

对于一般情况而言:
- 需要像素 > 图片像素:使用Linear
glTexParameteri(GL_TEXTURE_2D,GL_TEXTURE_MAG_FILTER,GL_LINEAR)- 需求像素 < 图片像素:使用Nearest
glTexParameteri(GL_TEXTURE_2D,GL_TEXTURE_MIN_FILTER,GL_NEAREST)第二个参数的意思是,当需求需求像素 < 图片像素的时候,采用什么过滤方式
Texture参数设置
纹理包裹
当UV坐标超出了0-1的范围,需要怎么做?
- Repeat:重复纹理
- Mirrored:镜像纹理
- ClampToEdge:边缘复用
- ClampToBorder:设置特定的边缘颜色并复用
glTexParameteri(GL_TEXTURE_2D,GL_TEXTURE_WEAP_S,GL_REPEAT)
glTexParameteri(GL_TEXTURE_2D,GL_TEXTURE_WEAP_t,GL_MIRRORED_REPEAT)- 要设置的对象是当前二维纹理
- 要设置纹理的哪个属性(u/v的wrapping 可以单独配置)
- 配置成哪一个值
示例2
做一个方形展示。
怎么做呢?两个三角形拼接起来呗,然后uv配置好,就可以做到
float positions[] = {
-0.5f,-0.5f,0.0f,
0.5f,-0.5f,0.0f,
-0.5f,0.5f,0.0f,
0.5f,0.5f,0.0f
}; float colors[] = {
1.0f,0.0f,0.0f,
0.0f,1.0f,0.0f,
0.0f,0.0f,1.0f,
0.5,0.5f,0.5f
}; float uvs[] ={
0.0f,0.0f,
1.0f,0.0f,
0.0f,1.0f,
1.0f,1.0f
};然后三角形的index,都需要向上,也就是
unsigned int indices[] = {
0,1,2,
2,1,3
};
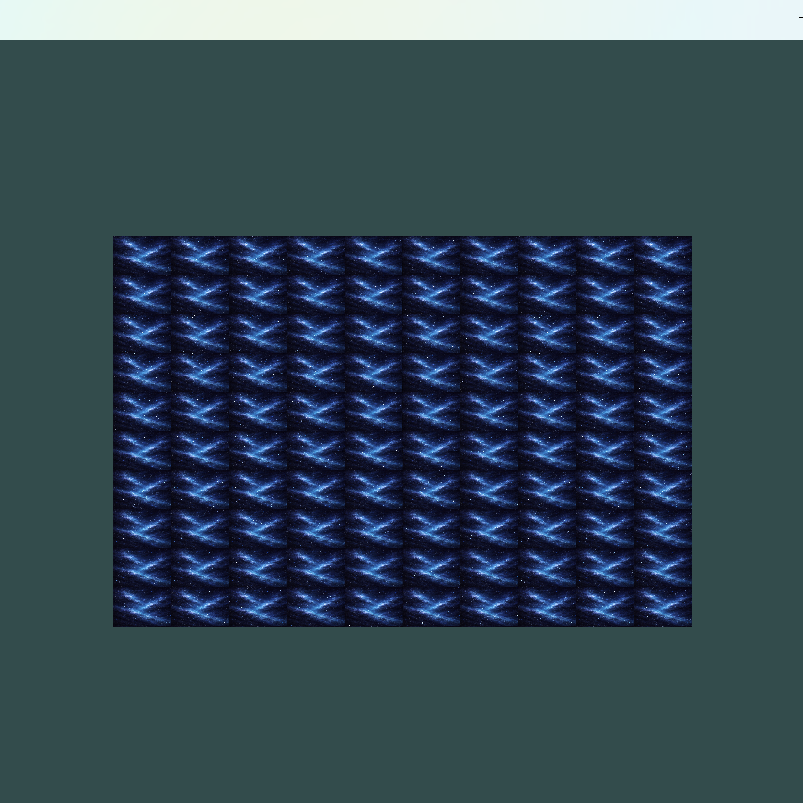
如何做到中间重复10次呢?那么其实就是uvs整体10倍,因为采用的是GL_REPEAT也就是重复纹理
float uvs[] ={
0.0f,0.0f,
10.0f,0.0f,
0.0f,10.0f,
10.0f,10.0f
};
轮播效果和代码:反正uv无限重复,只要随着时间变化就可以了。
纹理混合
怎么做呢?其实就是从图片上采样后,得到两个像素相加混合
void main()
{
// FragColor = vec4(color,1.0f);
vec4 tempColor1 = texture(sampler,uv );
vec4 tempColor2 = texture(sampler2,uv );
FragColor = 0.5 * (tempColor1 + tempColor2);
}当然,比例有时候也想要控制,那么可以加入一个噪声图

Mipmap
问题:距离很远的时候,所需要占用的像素不需要很大。这个时候就容易造成的贴图像素浪费,表达错误,毛刺感强,浪费带宽且不连贯,产生类似于摩尔纹。

问题:
- 图片信息被浪费了
- 相邻屏幕像素uv跨度过大,造成突变失真。
mipmap:为一张纹理图片,生成一系列的纹理图像。后一个宽是前一个的1/2。物体比较远的时候,自动切换为比较小的贴图。

生成方式
- 滤波:对图片进行模糊预处理
- 采样:对模糊的像素,选取像素组成下
滤波:
均值滤波:类似于池化,取周围很多个像素的平均值
高斯滤波:周边的像素不是平均过来,而是给与按照高斯分布的矩阵权重,中间高边缘低。
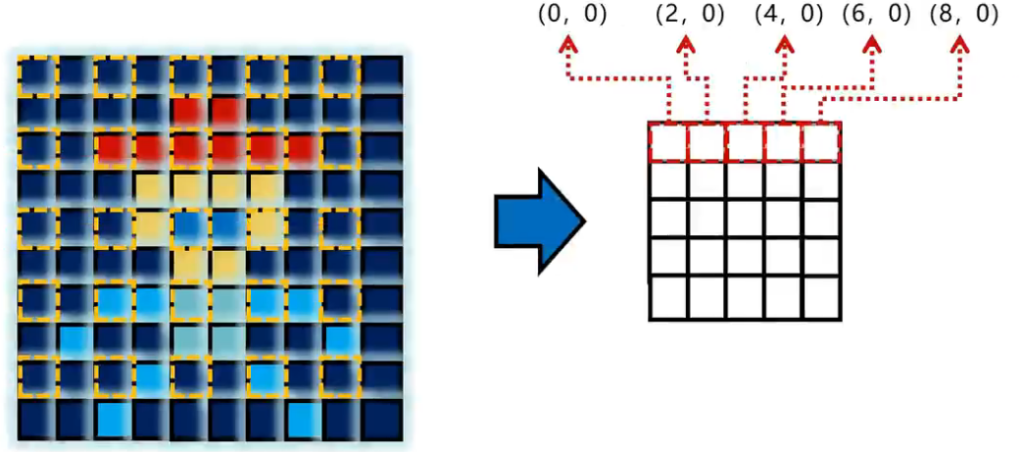
距离函数
Opengl如何判定应该要用下一级的mipmap了呢?
- 答:通过glsl中的求偏导函数计算变化量决定
对于GPU处理FragmentShader时候,不会每一个片元单独处理,而是编程一个2*2的区域进行处理。借助这个,我们可以计算出相邻像素在某些属性上的变化量。
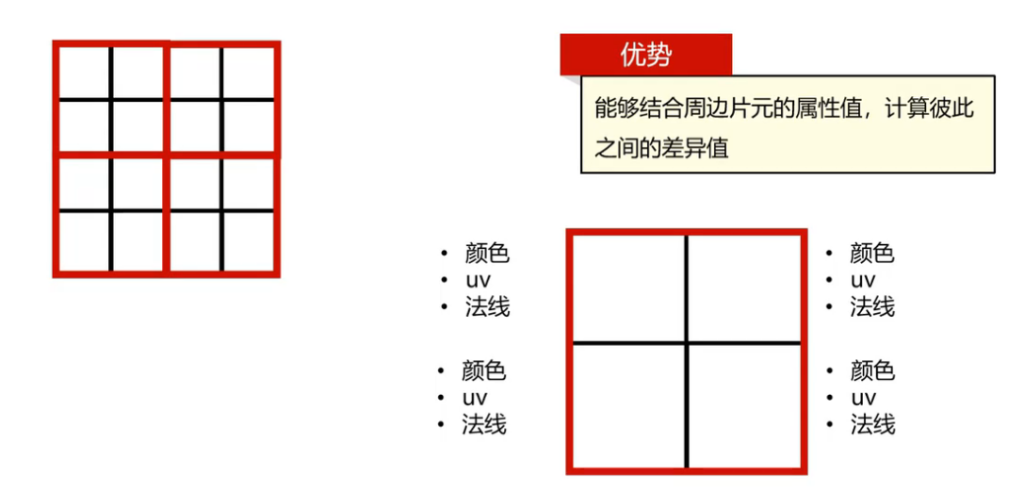
对于glsl中,内置了dFdx与dFdy,对栅格中某一个属性求偏导数
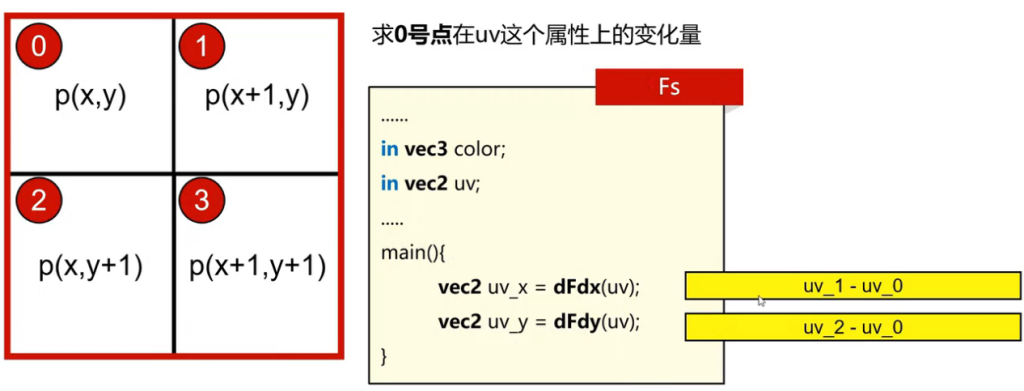
如何判定当前物体贴图是放大了还是缩小了?
这时候看1个像素,对应最终多少个纹素,如果对应m*n个,那么最后是对应log2(max(m,n))的级别。
距离判定
怎么具体判定呢?
可以获取当前纹素的变化量还有像素的变化量,然后去大的log一下就得到了具体的层级。


自动生成Mipmap
自动生成mipmap只需要一句代码
void glGenerateMipmap(GLenum target)- target一般为GL_TEXTURE_2D
- 设置自动采样方式,只需要一句代码
glTexParameteri(GL_TEXTURE_2D,GL_TEXTURE_MIN_FILTER,GL_NEAREST_MIPMAP_LINEAR)最后一个参数的前半段表示单张图片的采样方式,后一个表示不同mipmap之间如何选择
数学
摄像机