双压缩
LongCodeZip: Compress Long Context for Code Language Models
问题:虽然LLM很强大,但LLM压缩推理时候如果上下文过长,需要一定限制,不然导致信息丢失,性能下降。
传统的一些解决思路:
- LLMLingua:用小的transformor模型,对原始prompt 或上下文,语义保留的重写,信息压缩,关键词提取。实现来说就是用户一个输入,然后用这个小模型优化输入,再传递给上下文。
- Selective Context:不改变原文内容,从中筛选出一些最关键的信息,丢给模型。一般实现就是向量语义比对,然后TOP-K挑出最重要的
- RAG:面对一大段代码仓库,只通过文本相似度选取最相关的代码,再和prompt一起发给模型去处理。仅依赖文本相似性,没有考虑到上下文之中可能隐含的一些关系。
- DietCode:选择最重要的部分压缩(文件名,函数引用等关系确定),然后模块化构建上下文
- SlimCode:注重检索到的质量,而非TOP-K之类固定前几的数量。注重函数逻辑(文件名,函数引用等关系确定)
对于本篇文章,采用了两阶段压缩,粗粒度细粒度两次压缩
- Coarse-Grained
- 按照函数/类的自然边界切分(解析语法树之类完成保证稳定语法完整),并采用“近似互信息打分”
- 对于一段候选的上下文c,把它作为条件提供给模型,计算c加入后q的困惑度降低了多少。
- 好处在于可以捕获深层次的东西,不仅仅局限于表面的关联。可以更深入内部的联系。
- 通过把类或函数源码切割成多个chunk,然后逐个计算困惑度降低了多少,从高到底进行排序。贪心选取前几个函数,剩下位置用占位符保留结构。
- 对于边界情况,如巨形函数且AMI高,需要预定策略。根据需要保留完整性还是多装几个函数。如果不重要就直接跳过了。
- 对于AMI相近,引入一些次要判断要素比如短的先放,或者调用相关先放。
- 对于一段候选的上下文c,把它作为条件提供给模型,计算c加入后q的困惑度降低了多少。
对于粗预算,用 总预算/压缩率 得到,然后困惑度高到低依次加入,保证不超过这个数目。然后在细粒度时候,保证不超过总预算。
- Fine-Grained
- 语义分块:找出多个逻辑独立内聚的代码块
- 采用困惑度感知,每一行作为一个基本单位,计算每一行的困惑度关系。找出困惑度的波峰,就认为是语义边界
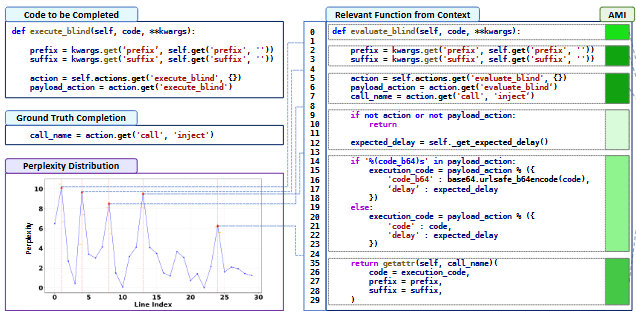
- 采用困惑度感知,每一行作为一个基本单位,计算每一行的困惑度关系。找出困惑度的波峰,就认为是语义边界
- 自适应预算分配
- <5行直接放,直接放保留预算。
- 剩下大函数根据差值比例算,得到一个总的保留比例基准线。然后根据函数重要性(依据AMI),倾斜线性比例分配。
- 动态背包选择
- 最后每个函数都有了自己的预算,也有了自己的分块。现在在预算不超过B_i的情况下,按照之前的分块,挑选出价值组合最高的块。此时问题转化为经典的0/1背包问题,组合后可以得到最大的情况。最后就可以最大化的保留有效信息。
多轮智能体
Improving the Efficiency of LLM Agent Systems through Trajectory Reduction
背景:智能体每一步调用工具后,工具调用与结果会追加到后续输入,从而导致后续出入过长冗余。存在三类的主要废料:与任务无关的噪声(构建输出模版导致的),重复信息(参数与结果重复,多出重复出现代码),过期的信息(排查过程中和最终故障无关的内容)
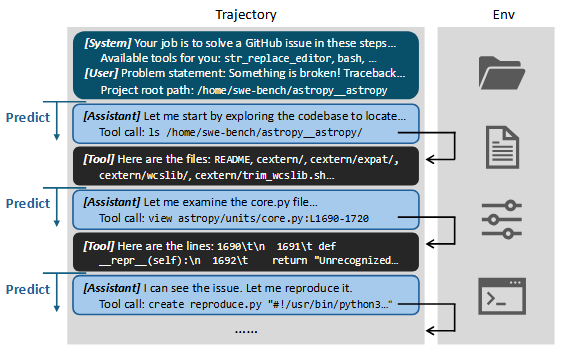
作者尝试去网模型内部内置erase,不过模型更倾向于去做事而非清理,即使有明确的指示。因此作者采用外部强制触发的方式去做。
那怎么实现?简单来说,就是当执行某一步骤之后,就把之前一些步骤的信息给整合一下。整合的过程也是交给LLM模型,但是可以用一个小的便宜的LLM就可以。
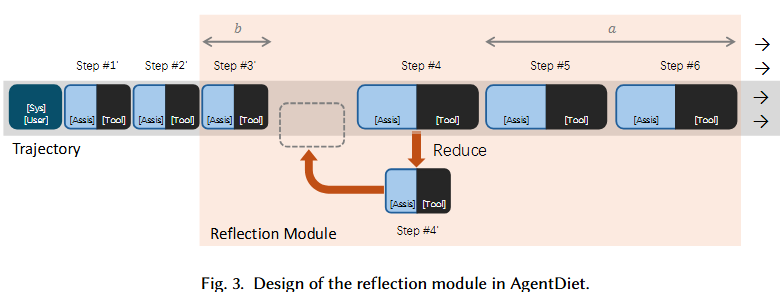
当智能体到s步骤的时候,反射模块只允许减少步骤s-a中的内容,只给固定的上下文(s-a-b到s);同时也配置一个阈值θ,只有当目标文本长度超过阈值且压缩收益也超过阈值才生效。从而避免改写最新状态,把之前无效内容影响降低,接着保证一定会有一定收益。兼顾了稳定性和成本。

开始先执行agent的一些任务。
当每一步主模型完成之后,环境执行该调用并把调用与结果追加进轨迹。
下面开始反思步骤。步骤在区间内,长度超过θ就序列化窗口上下文,按照上面的把s-a-b到s的内容提供给模型,压缩s-a这一步。
如果收益超过θ,就用新版本替换轨迹中的这一步(s-a)
最后,继续持续推理,直至任务全部完成。
同时,采用s-a,而不是最近一步还有优势,有利于KV缓存和时延;因为Transformer推理的时候,会缓存前缀token的Key/Value,部分服务商对于复用前缀优惠。因此修改尾部的部分可以省钱且快一点。因此虽然每一轮反思会增加一些开支,但是主模型那边前缀相同且更短了,可以很大程度上抵消。体感上延迟不会增大很多。
但如果时延特别敏感,其实就可以并行。小模型和主模型同时做,这样代价是压缩可靠性下降,但是等待时间更短。
长程多步交互LLM代理压缩框架
ACON: OPTIMIZING CONTEXT COMPRESSION FOR LONG-HORIZON LLM AGENTS
问题:长程多步交互的LLM代理中,有时候需要再几十上百步的交互中保留动作,观察历史和环境状态,导致上下文无限制的增长,增加了推理成本,也使得模型被无关信息分心。
由于场景多,需求广,缺少能够跨任务/泛化的压缩准则。采用手工模版几乎不太可行。
基本解决思路:把“怎么压,压什么”做成一个可学习的目标,然后数据闭环的不断去优化它。专业点就是借助LLM学习,得到给出压缩提示词的prompt模型。
在不改动代理本体的前提下,用一个“压缩器”把需要喂给代理的历史与观察变短,但又不丢掉对后续决策必需的关键信息。难点是“哪些该留、哪些该丢”在不同任务和环境里差异很大,靠手工模板或一次性的提示词很容易失真。ACON的关键点是把“压缩准则”本身当作一个可以学习、可以迭代优化的“自然语言指南”,用成功与失败轨迹对比提供监督,反复打磨这份指南,直到既稳又省;再把学好的压缩器蒸馏成小模型,以便便宜、低延迟地用在生产代理外侧。
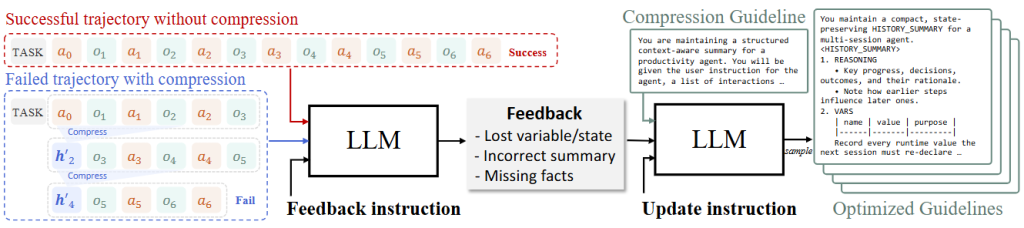
先用现有指南试压一遍,和无压缩且成功轨迹做对比。如果失败,定位哪里“压坏”了(借助一个强LLM),然后修正指南以防止再犯;如果成功,则同样借助强LLM找冗余瘦身,学习经验。最终得到一个稳定且cost小的指南。如果需要,可以再对这个经验蒸馏得到小模型里面。
问题的优化函数是这个:
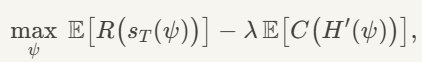
也就是说,我们需要最大的优化任务的回报,和最小化任务的代价。训练时候先把任务回报尽可能做高,然后再降低cost
任务的代价就是上下文文本,token长度。任务的回报怎么量化呢?
基本就是借助EM(精确匹配)/FA(模糊匹配)
RL采样
PIS: Linking Importance Sampling and Attention Mechanisms for Efficient Prompt Compression
PIS:提示词重要性采样。采用双层采样(token级+句子级)
优点:采用RL自适应压缩比,双层采样抽取
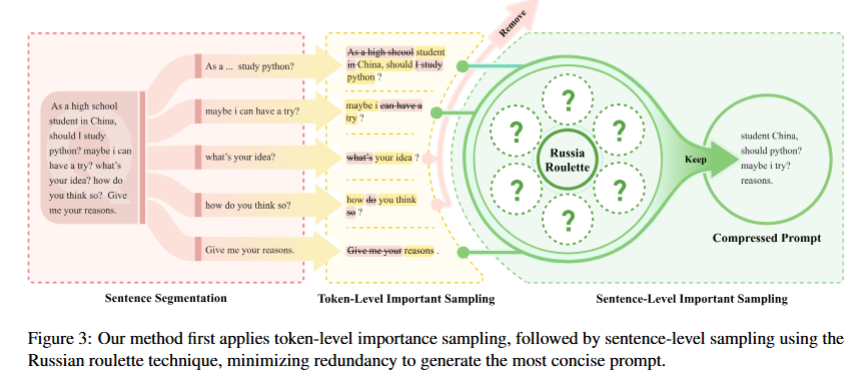
Token级重要性采样上,没采用LLM抽注意力(贵),采用小型encoder-only模型近似计算句内token注意力/相关性排序,依据是好的encoder在相对关系上与大模型一致。为保证删除正确,引入注意力方差,删除过高的(防止只是局部的关注/不关注);同时用IF-IDF矫正,避免删去兼具词频和语义词。RL Model会同时考量压缩率、语义保真与流畅度,使信息密度高句子保留多,低的保留少。
Sentence级重要性采样上,把每个压缩好的句子用一个小型编码器映射成向量,然后顺序处理句子。如果和之前句子相似度低,就加进来(因为是新信息),相似度高就用“俄轮”,即连续相似句子越多被删概率越大。
动态压缩提示
Dynamic Compressing Prompts for Efficient Inference of Large Language Models
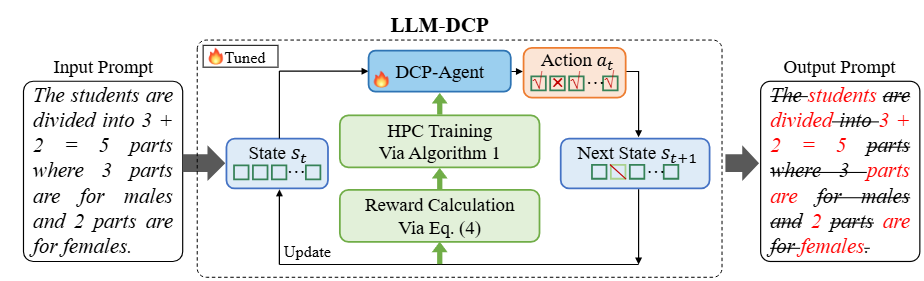
方法:PPO强化学习,把压缩整个过程视为马尔科夫决策过程,寻找压缩与保留语义最优解。
优点:可同时关注压缩率,信息保留率以及LLM输出一致性多个指标,也可在训练时有所侧重。
把压缩过程建模为一个MDP,奖励函数参考四个部分:压缩率,关键信息保留率(BERTScore),输出分布一致性(KL散度),边界惩罚(保证稳定性)。训练上层级增加难度,助于稳定高效收敛。
这里,输出分布一致性指的是在修改前后,大模型输出的变化。当然作者也没真的调用大模型,用了个小模型对齐训练,降低开销。
整体性评估
Understanding and Improving Information Preservation in Prompt Compression for LLMs
作者提出,评估提示压缩技术不应该只看结果,应该看多个方面
- 下游任务表现。使用压缩的时候,具体的任务表现如何?论文使用了BERTScore(文本相似度)和Exact Match等指标来衡量。
- 响应的接地性 (Response Grounding):评估模型输出有多少多大程度忠于原始未压缩的文本,采用了FABLES (https://arxiv.org/abs/2402.10214) 的方法,可以从模型生成回应中提取关键声明,并于原始做对比,从而判断其真实性
- 信息保留度:保留率多少原始信息。方法是让LLM根据压缩后的提示重建原先的文本内容,然后比较这二者相似度以及关键信息保留比例来量化保留程度。
在压缩方法上,作者基于软压缩改进。为了保证关键信息不流失,提出了两种改进方式:
- xRAG w/ Sentence PT + FT: 这个版本在预训练(Pre-Training)和微调(Fine-Tuning)阶段都以单一句子作为基本单元进行压缩。这样训练出来的模型能更好地理解和编码句子级别的精细信息。
- xRAG w/ Two-Step PT + FT: 这是一个更进一步的改进。作者发现,即使在句子层面进行压缩,模型也需要学会如何整合来自多个句子软提示的信息。因此,他们设计了一个两阶段的预训练过程:第一步学习压缩单个句子,第二步学习理解由多个句子压缩而成的软提示序列。
转化压缩任务为分类问题
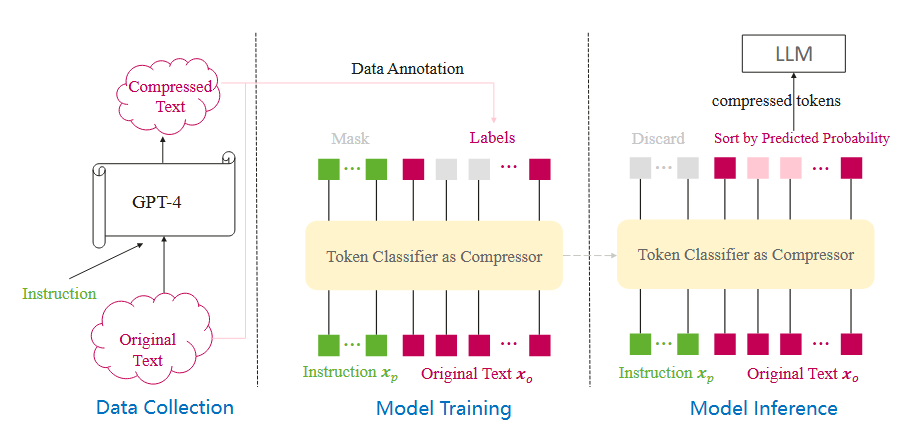
EFPC:将提示压缩任务转化为一个令牌分类问题。即训练一个模型,来决定原始提示中的每一个token是应该留下来还是应该丢弃。
流程分为三步:
- 指令感知的数据收集 (Instruction-Aware Data Collection)
- 传统生成训练数据,会让教师模型去缩写文本,而EFPC则是在此之外,还要求提供一个相关指令(提供一个具体的问题)。要求教师模型提供的问题可以被缩写后的内容解答。
- 这样可以得到大量数据对,便于模型在后续使用
- 使用一个轻量基于Transformer编码器(Encoder)的架构(multilingual-BERT)。把任务定义为一个二元分类任务,对于输入的每一个词源,都需要判断留/丢弃
- 输入基本格式为 [用户指令, 原始文本] ,如果需要特定任务压缩,就输入用户指令。通用压缩就为空。
- 一致性训练:先让模型内自注意力,这样用户指令作为提示信息与文本交互。在计算损失时,我们完全忽略模型对
用户指令那部分的预测结果。有利于模型注意力集中在更重要的部分。
- 模型推理与压缩:
- 当用户需要压缩长指令时候,将用户指令(如果有)和原始提示输入到训练好的EFPC模型中。模型会根据原始提示中的词源输出一个保留概率分数;最后根据压缩率目标,选取概率分数比较高的一些词源,得到最后提示。
任务无关压缩
如果任务本身没有明确的问题,那么很难清楚我们需要怎么去压缩(例如,开放式的文本摘要、代码补全等),通用性差。本论文核心解决“问题依赖局限”,自适应解决不同问题的压缩。
任务分成两步,先让模型自己从长文本中生成一个“任务描述”,然后用这个任务描述来指导压缩过程。
仓库级代码补全
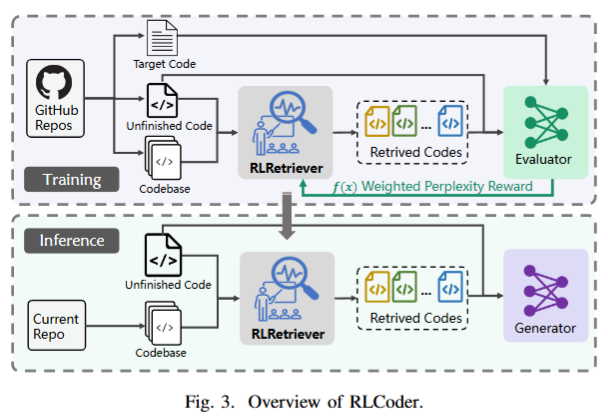
RLCoder: Reinforcement Learning for Repository-Level Code Completion | alphaXiv
局限性:无法读取庞大仓库代码
解决:RAG,查询出最相关代码和上下文一起投喂大模型,生成补全最后结果。
问题:
- 依赖标注的数据
- 基于模型的检索器可以理解代码,但是训练很费时,且难以泛化。而传统的基于关键词的检索(BM25)很难捕捉深层关系
- 候选片段构建问题
- 如何将代码文件切分,一般而言难以保证其连续性和完整性,上下文质量不高
- 非选择性检索
- 部分代码补全只需要当前文件上下文即可,而有些却需要参考其他文件。需要加以选择
解决
- 对于问题1,RLCoder不依赖人工标注数据,在训练时候随机从代码片段挖取一部分,检索器是从代码仓库中选择一个候选片段,交给“评估器”(代码大模型)去预测挖掉的代码。
- 评估标准是能否让模型以更低的困惑度生成代码。
- 对于代码中重要的部分,给予更高的权重
- 对于问题2,按照函数和类的自然边界划分。
- 对于问题3,作者人为添加一个空候选。在检索时候,如果检索器较早的选择了这个“空候选”,就相当于发出一个信号不需要额外的其他信息了。此时检索就会停止。
微调
学习使用 Gist 标记压缩提示 |阿尔法十四 — Learning to Compress Prompts with Gist Tokens | alphaXiv
核心机制是在指令微调阶段,修改Transformer的注意力掩码,“强迫”模型学会压缩。
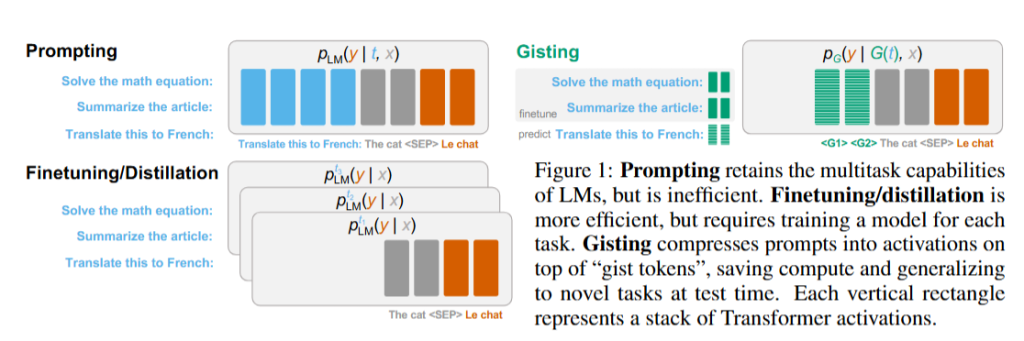
对于一个 [提示 t] -> [Gist Tokens g1…gk] -> [用户输入 x]”Translate to French:”<G1><G2>”The cat”,中间加入GistTokens,Gist Tokens只能看到自己和之前的内容,而用户输入只可以看到前面的Gist Tokens。为此,模型将被迫在微调阶段学会压缩。
对于模型在推理阶段,也可以把一些内容Gist压缩下,下次输入和新的用户请求一起拼起来。
编码器-解码器极高效率压缩
500xCompressor: Generalized Prompt Compression for Large Language Models | alphaXiv
极高效率压缩,感觉更像是做概括内内容。
- 编码器 (Encoder):编码器使用的是一个冻结的 LLM(例如 LLaMa-3-8B),但在其上附加了可训练的 LoRA 适配器。它的任务是读取原始的长文本(比如500个token),并将所有信息“注入”到少数几个(例如1、4或16个)特殊token中。
- 解码器 (Decoder):解码器就是原始的、完全冻结的 LLM,没有任何改动。它接收来自编码器的、携带了全部信息的特殊token,并根据这些token来执行下游任务(如回答问题)。
- 关键创新点:与基线方法 ICAE 主要压缩和传递token的嵌入(Embeddings)不同,500xCompressor 压缩和传递的是这些特殊token在LLM每一层中的键值对(KV values)。论文认为,KV值能够比单一的嵌入向量携带更丰富、更全面的信息,这是其能够实现更高保真度压缩的关键。
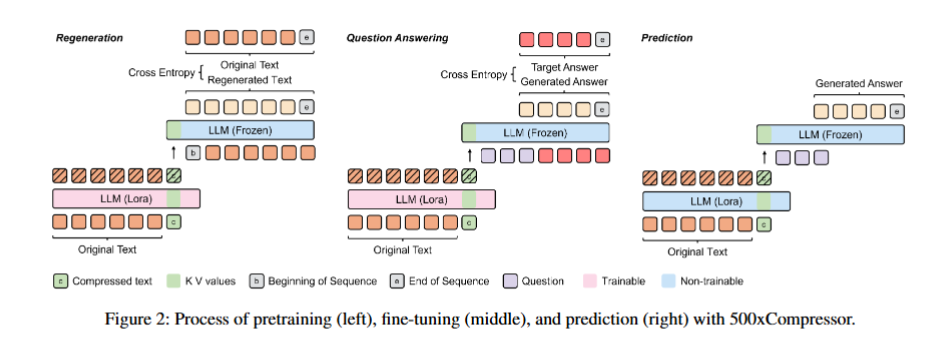
预训练:学习把压缩后的token里面的内容重建出来
微调:学会让模型在压缩文本的基础上回答问题