Unified Multimodal Understanding via Byte-Pair Visual Encoding
标题来看,通过 字节对视觉编码 实现统一的多模态理解,嗯抽象
论文核心思想,是把自然语言中的BPE(Byte-Pair Encoding)分词技术应用于视觉领域[传统的是利用视觉编码器(CLIP)],从而为图像文字共同创建一种统一的,离散化的表现方式。
两个问题,什么是自然语言的BPE,什么又是CLIP
- BPE(Byte-Pair Encoding)
- 原理上:对于模型来说,如何理解一个单词比较麻烦。最简单的是单个字母来,对于例如happy,那么就可以直接h-a-p-p-y,形成一个完整的单词,不过这样对于模型计算来说,理解一个词成本就非常非常高。
当然可以直接整个单词就转化为一个向量,但是这样就会导致词汇表过于庞大,且不便于扩展,如happy和happiness,这两者是存在一定关系的。
这里的一个思路,有点类似词根词缀。即我们把一个单词词根词缀提取出来,把这些都当做一个整体,类似于我们看到work和worker,我们拆成work 和 er。那么对于词汇表就只用记录这两个向量,且具有良好的扩展性。 - 实现上:感觉有点类似于哈夫曼树。找出频率最高的部分,提取把他们作为一个子部分,循环往复,达到自己预想的效果为止。
- 原理上:对于模型来说,如何理解一个单词比较麻烦。最简单的是单个字母来,对于例如happy,那么就可以直接h-a-p-p-y,形成一个完整的单词,不过这样对于模型计算来说,理解一个词成本就非常非常高。
- CLIP
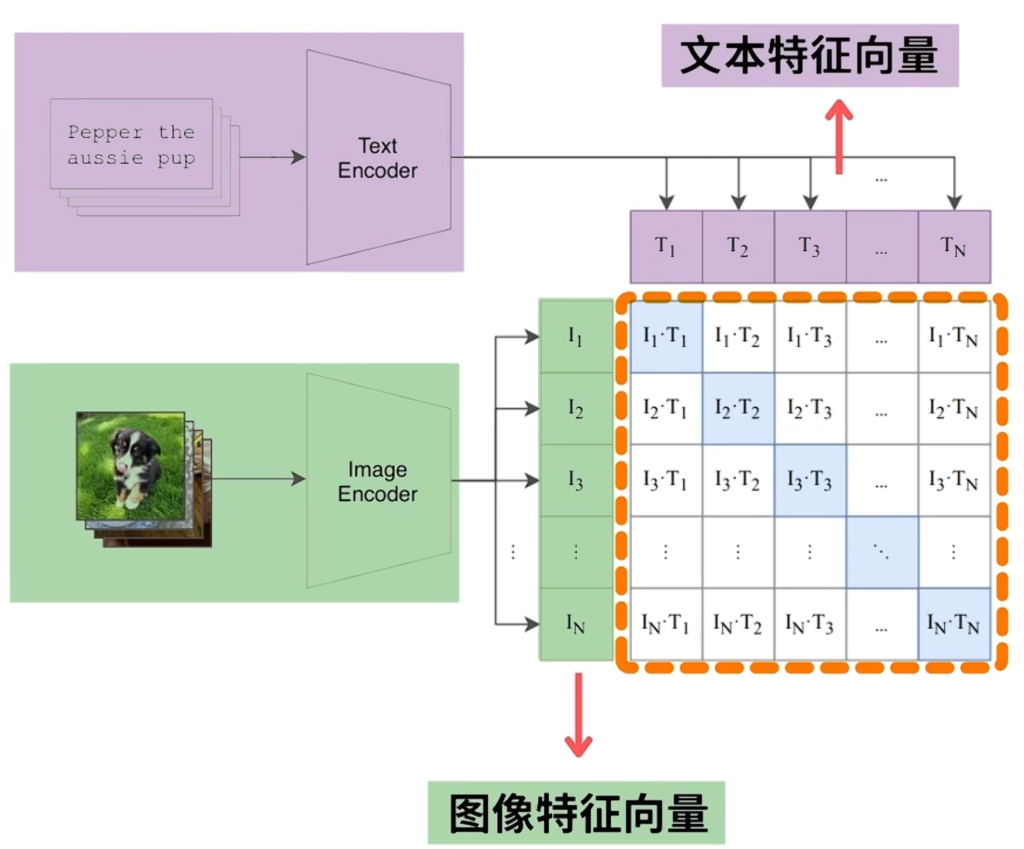
- 原理:可以把文本的向量特征和图像的向量特征都放在同一个特征空间中,这样我们就可以判断图片和文本的相似程度(点积),从而做到图生文or文生图这样基本的模态转化。
- 训练:这个Text Encoder和Image Encoder都是别人做好的。因此这里就相当于找二者的映射关系。训练可以去找大量的文本和图像对,对比预训练得到这么一个关系。训练目标就是尽可能最大化匹配对相似度,最小化不匹配对相似度。最后得到映射关系就可以把他们放在同一个语义空间里面了。
然后现在两种基本的方式,一种是连续表示,一种是离散表示
- 连续表示
- 何为连续?不都是多维的向量吗?
- 那当然不是,连续对应的是数值。例如前面得到了很多特征,对于每一个特征维度的值,我们可以无限细分去表示,例如[0.1234…, -0.9876…, 0.4567…]这样在数学上是连续的。那么可以说这个狗的特征多少,田园的特征多少,可以无限精细的划分。
- 何为连续?不都是多维的向量吗?
- 离散表示
- 对于向量,取值是有限可数的。一般ai中表示为整数,即[5, 89, 1024, 77, …]类似这样。那么,我们就找不到一个在3和4之间的数字,它就是离散的,不存在中间档位。同时对应的大小必然也是有限的。
- 这样相比于上面,必然受限于精度从而导致信息损失了。
很明显,上面的连续表示不是更好吗?对于图像表示不是更加的精确吗?为什么还要下面
对于人类文本来说,就是一些离散的token。所以LLM专门为离散的toekn设计的。那么LLM和这个图像编码器就没有办法很好的交流。有点像图形学光栅化问题,采样过高过低都会带来严重的问题。
然后回到论文,两个创新点。一个就是编码之后,自然也可以用类似的方法,把一些一样的块合并一下,就是上文提到的BEP方法应用于图像上。论文里方法就是找出水平和竖直的这个ID对,然后统计出现频率,高的话就变成一个组。这个组是有向性的,需要记录相对位置信息,以保证信息的准确。例如眼睛在睫毛下面。反复迭代到一个合适的水平。
第二个创新点,对于训练策略从浅入深。这个倒也好说,毕竟不可能一蹴而就的。
步骤来说三步,第一步就是前面那个,先合并合并找出一堆块,把这个块作为离散的特征向量块
第二步就是把这个特征token,喂给LLM,让LLM实现语义的理解
第三步微调,前面理解语义了要输出长句子才行。给点规范输出,让他推理输出一些长句子。
几个问题。
- 文章做的是离散的语义转化,那为什么不直接一开始对连续的数值直接映射到离散,不就解决了吗?
- 不可以。这样语义之间的复杂关系就被cover了。不清楚连续值的关系,直接的映射会丢失原本的信息,且我们不知道这个映射后的语义。本文做的应该是,通过前面的挖掘后,得到的那些块,最后在给LLM去训练,学习用这个去生成语言。
Generative Agents: Interactive Simulacra of Human Behavior
核心目标是制作出一个类似于真人生活的智能体。传统NPC毕竟程序固定,行为逻辑都是可预测的。
作者为此做了一个Smallville,在这个沙盒里面,放置25个智能体。模拟他们类似的真人生活,他们拥有自己的身份人物关系之类的。
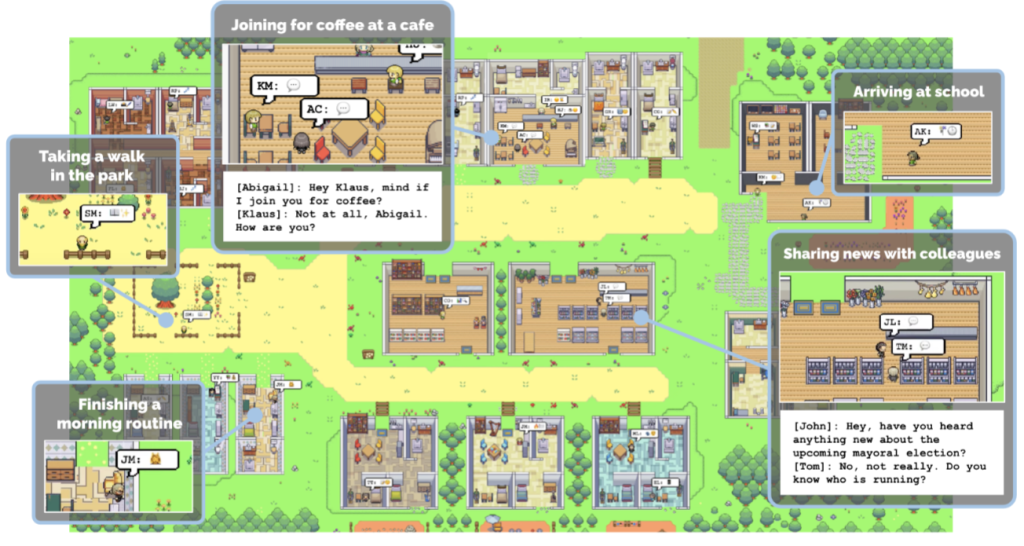
初到这个模拟,个人觉得最大的问题是如何保证长期的记忆。角色扮演到后续不可避免出现的遗忘问题,可以压缩,但也容易忽略掉其中的细节。至于决策行为来看倒还好说,基于自身的一定条件,交给大模型应当可以输出一个当前的决策。
作者的话,做了一个智能体架构,分为三个模块
- Memory Stream
- 记录智能体所做的每一件事情或者观察到看到的事情,符合人的一般情况。
- 问题:还是前面的遗忘
- 处理:Retireval。需要决策的时候,根据三个维度,也是参考人的感觉:
- Recency:越近越觉得重要
- Importance:不同事件有不同重要性
- Relevance:和这个决策的相关性
- 根据以上内容,加强检索出一些东西
- Reflection
- 智能体不会只是单纯做事,也会周期性的回顾最近的记忆,并提出一些比较有深层次的问题,然后利用模型对这些问题回答,生成一些insight。最后把这些insight也存进memory stream里面。后续就可能影响自己的认知决策。
- 相当于人们日常对自己所做行为的一些反思。
- planning
- 长期规划:基于身份经历,制作一些长期的日程表
- 短期规划:基于长期计划分解为短期内跟价具体和短的行动。
- 反应调整:当智能体观察到一些新情况,可以决定是否互动,然后计划也就会调整。
结果:
- 信息扩散
- 比如Sam要选镇长的事情被传来传去,很多智能体都知道了
- 情人节派对被所有人知道了。。
- 关系形成
- 不认识的智能体,通过一些事件交流之后,逐渐的熟络起来。
- 集体协作
- 智能体会记住以前的一些决策,并未后续做出一定努力
确实存在一定的社会学意义,emm这几个结果来说蛮有用的。在一定程度确实可能可以模拟
不过作者也看出来问题的局限了,语言过于正式,社会学认知不足,成本太高了之类的。
自己的话还有几个问题:
- 事件可以精细到什么程度?同时出现在公园或者酒吧之类的,就会产生事件认识?还是需要一定的条件
- 精细程度全看定义or决策了。可以非常精细再加上动作,因为反正llm生成嘛,加很多戏可以。
- 认识来说,在同一地方不会就认识。而是比如说模型根据过去检索下,看看自己有没有必要去认识。反正多方面共同决策,把多个方面一块放进prompt里面。最后的时候llm进行决策,要不要认识或交互。
- 如何感知的。是否存在一个统一的事件管理?二者如果偶遇或者路过,是什么通知他们知道这件事,又是什么判定条件让他们可以交互。
- 存在一个Sandbox Environment Server,上帝视角知道一切。对于每一个智能体,存在一个感知范围,可以知道这里面发生了啥。如果在感知范围内,那么这个Server就去推送给智能体。
不过即然都有一个Sandbox Environment Server了,那为什么做不到社会学的正常认知?
好吧作者也意识到就是没做,,,,,,,好
Beyond Pipelines: A Survey of the Paradigm Shift toward Model-Native Agentic AI | alphaXiv
对于Agent构建,主要有两种设计思想
- pipeline-based paradigm
- 规划:通过chain-of-thought提示词,让模型思考每一步的动作
- 工具使用:设计React 遮阳外部循环框架,让模型可以思考行动之间切换
- 记忆:构建一个Rag的系统
- 本质:很pasitive,难以应对流程之外的情况
- Model-native Paradigm
- 规划:例如DeepSeek-R1之类的,让模型学会自己去思考规划使用工具和记忆。让这些能力内化后,成为模型自己本身能力的一部分
- 工具:自身调用,自己生产相关的调用代码
- 记忆:主动管理上下文
- 本质:主动决策,现在高级智能都会做
在RL部分,借助LLM的RL可以提高效率,不必像传统RL一样从头开始学习,因为模型本身带有一定的先验知识。
Multi-Agent Collaboration via Evolving Orchestration | alphaXiv
问题:现在的多智能体,处理问题时候都是静态的过程。简单来说都是认为规定好的处理路径,但这个路径真的是最佳吗?一般来说,现在这些过程具体来说要么线性,要么树状图状,总之路线相对固定,效率低可扩展性很差。
解决:Dynamic Orachestration(动态编排)。把前面静态的处理过程变成一个可学习的动态过程。借助RL自动学习排序和调度,从而灵活推动进度。
那怎么实现的?RL强化学习不断优化。
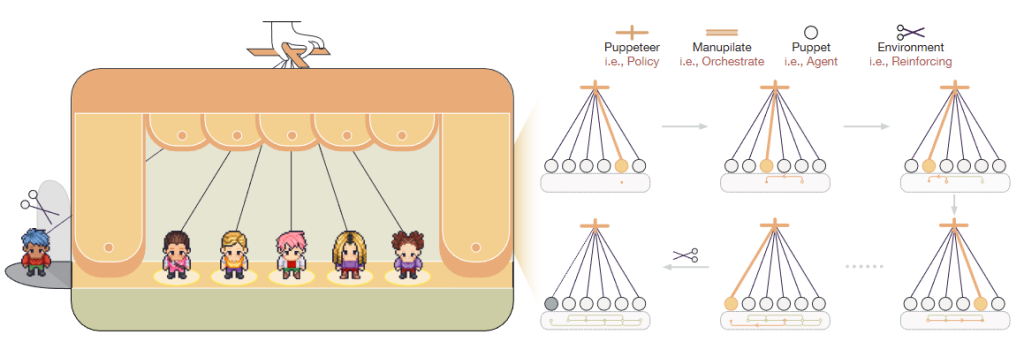
- 先两个形式化定义
- Agent :a = (m, r, t) m是模型,r是推理模式,t是可用工具集
- 多智能体系统 (MAS):G = (V, E) 看成有向图,V是agent集合,E是信息流
- 架构设计上
- 一个中心化的Orchestration,智慧选择智能体,安排决策任务
- 序列化上,建模为一个马尔可夫决策过程 ,基于之前模型生成的内容,交给中心化那个Orchestration,决策下一次使用什么Agent,得到生成内容。如此循环直到任务完成
如何借助RL可以呢?RL所做的是让协调过程不断优化,基本也是设定一个奖励函数,当高质量低成本完成任务就奖励。
R_t = γ * R_{t+1} – λ * C_t:r是任务的分,C_t是每一步得分。可见步骤越多分越低。
最终模型学会:剪枝,优化路径,平衡表现与效率这些,达到一个好的平衡效果
DreamGarden: A Designer Assistant for Growing Games from a Single Prompt | alphaXiv
好大的野心,希望构建一个从prompt到一个游戏原型
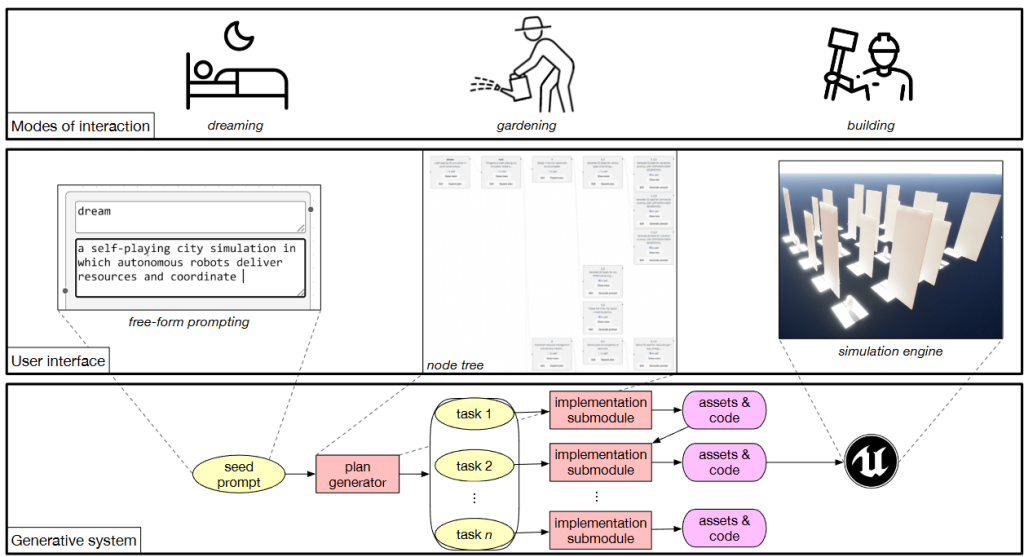
总结概述一下,开始一个prompt,根据这个生成详细的任务,最后不断完成这些任务最终完成游戏。
可以很快的完成一个相关的游戏原型构建,步骤就是上面这些步骤,详细来说:
- 开始提供一个prompt,先生成broad plan这种宏观规划,然后再对后面的这些细节去优化,生成每个子模块的细节plan,递归循环直到所有任务都规划完。然后最终得到一些列任务
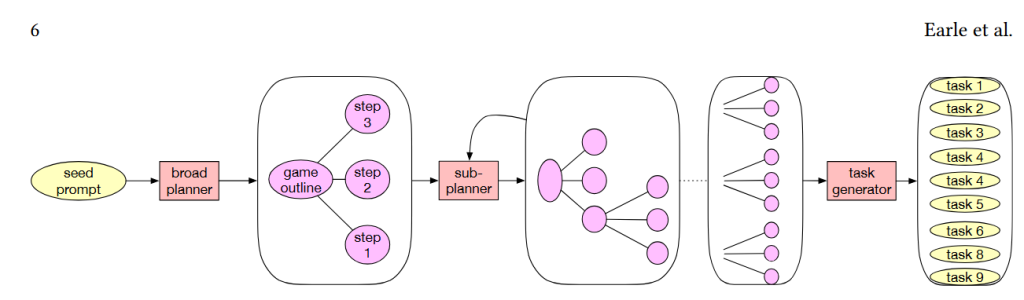
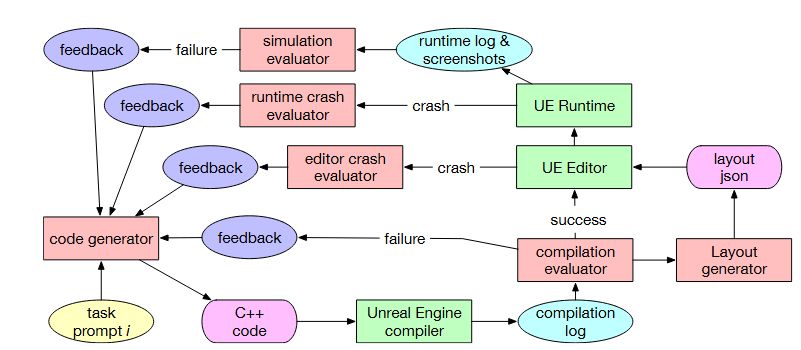
- 对于代码生成部分,会先根据前面描述生成一个详细的提示,然后生成cpp代码。接着去编译,根据错误,自动的反思优化,不断的尝试。直到任务解决或者到达一定失败次数后放弃
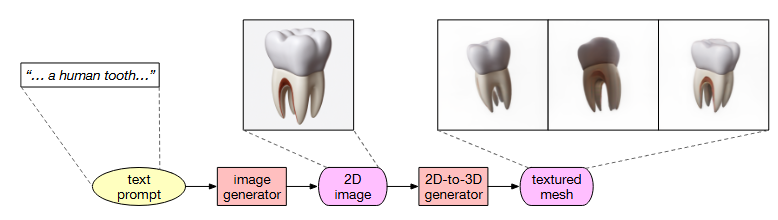
- 接着是模型怎么出来呢。先把前面的描述,比如说一颗牙齿什么的文生图,然后再图生模型,再一些格式转换就可以用了
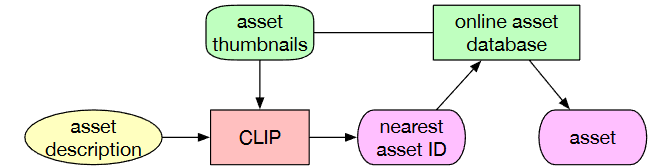
- 对于需要下载的资源,根据文字相似度找到最相近的。比如说一把木制椅子,就根据这个去资源库搜索,把最相似的下载回来用。
那么,用户肯定也需要对进度了解或者中间时候修改吧。可以选择对哪一步修改,比如减枝或者扩充某一部分。那如果发现游戏哪里不对劲,也可以写prompt,让整个去修复

这里说建筑怎么都在飞,没有平地之类的。就会开始自动调用修复。这里会去寻找依赖,在这个时间点后的部分都会被废除重新生成,以保证明确的正确性。