想要短期冲刺?
想要扎实点?
https://awesome-programming-books.github.io
C++基础知识
智能指针
为什么有?因为很多程序员申请指针后,忘记释放,导致内存泄露。
智能指针可以很大程度解决这个问题,其本质就是一个类,超出作用域后自动释放资源,避免这个问题。
auto_ptr(所有权)
每一个指针是唯一的拥有者。后续已经废弃
auto_ptr<std::string> p1 (new string ("hello"));
auto_ptr<std::string> p2;
p2 = p1; //auto_ptr 不会报错
cout << *p1 ; // 炸了为什么会这样?因为根据设计理念,你已经把所有权给p2了,那你的p1就没用了,应该去释放。同时,如果指向资源,那你多个智能指针指向同一个,资源就会被释放多次。
unique_ptr
为了解决上面的问题,这里不能够直接通过 = 来赋值,必须通过move来转译控制权。一定程度上保证了安全。
unique_ptr<string> p3 (new string (auto));//#4
unique_ptr<string> p4;//#5
p4 = p3;//此时会报错shared_ptr
unique_ptr用着不方便,有时候确实要多个指。
因此使用shared_ptr共同管理资源,那怎么实现这个“智能指针”呢?这里会引入计数器,当所有的shared_ptr都被销毁,那它就会释放管理的内存。
那么为什么要make_shared?这个就相当于直接构造了,
问题:两个互相引用,不就永远无法释放了?
weak_ptr
为了解决shared_ptr可能的循环引用问题,用一个weak_ptr辅助shared_ptr。
特点:作为观察者,不会给shared_ptr增加计数,但也不可以访问资源,只能看资源有没有被释放。如果要使用资源需要通过Lock方法转化为shared_ptr才可以(此时便不会有循环引用,因为转化的先被释放回去,不影响原先另一个shared_ptr)。
#include <iostream>
#include <memory>
class A;
class B;
class A {
public:
std::shared_ptr<B> b_ptr; // A 持有 B 的 shared_ptr
};
class B {
public:
std::weak_ptr<A> a_ptr; // B 持有 A 的 weak_ptr
};
int main() {
std::shared_ptr<A> a = std::make_shared<A>();
std::shared_ptr<B> b = std::make_shared<B>();
a->b_ptr = b; // A 持有 B
b->a_ptr = a; // B 持有 A 的 weak_ptr(不增加引用计数)
// 到这里,a 和 b 的引用计数都为 1
return 0; // 程序结束时,资源正常释放
}内存分配
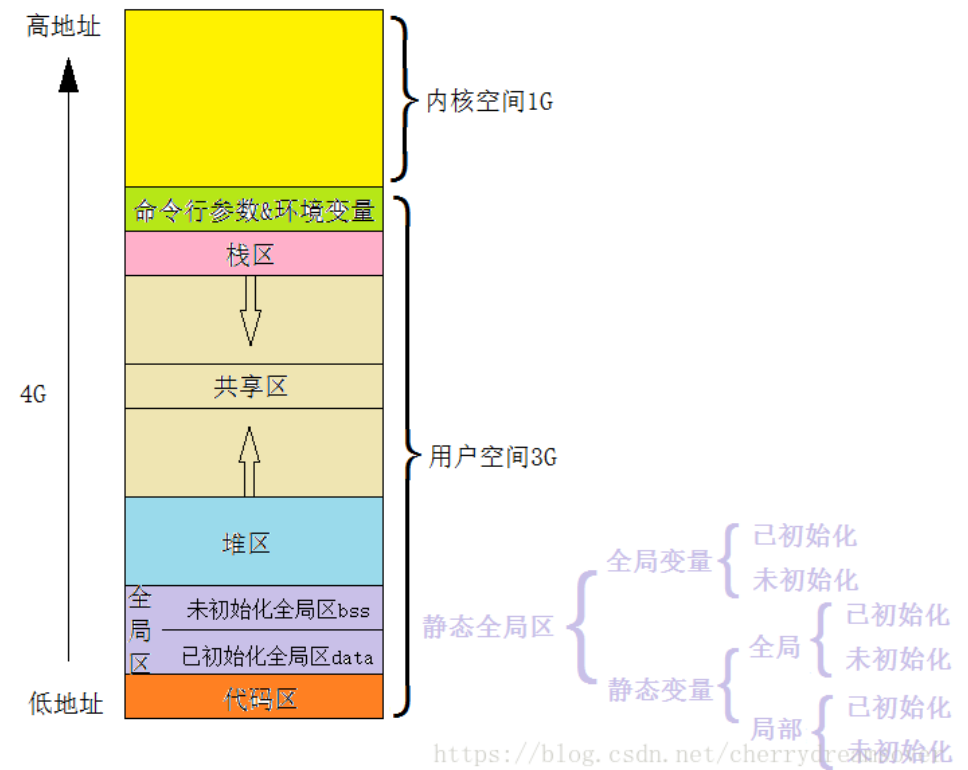
- 栈区:存放局部变量,临时变量,函数参数等。由编译器自动管理,分配速度快,适合小规模数据。
- 特点:先进后出(就是栈的特点),函数返回,栈上临时变量都杀了。
- 堆(Heap):存放malloc new出来的空间。程序员手动管理,适合大规模数据。
- 分配比较慢,而且容易内存泄漏,空闲碎片等。
- 名字就是早期习惯,和堆一点关系没有。
- 全局/静态存储区:存储初始化和未初始化的全局/静态变量
- 常量存储区:存储常量
- 代码区:存储二进制代码(包括所有函数代码,只读)
指针参数传递和引用参数传递
指针传递本质仍然是值传递,即新建了一个临时变量,复制了指针的值。这对于指针当然不影响,指向地址不变,所以你仍然可以修改原先的值。
引用的本质是起别名,编译器转换过来后就没有额外开销了,因为不会注册新的变量。在作为函数参数的时候,放过来的是实参变量的地址,切绑定后不可以更改了。
语法上,指针要显示解引用,而引用就直接用就好了。
int a = 10;
int& ref = a; // 不分配新内存,ref就是a的别名
int* p = &a; // 分配了8字节(64位系统)存储地址Const和Static
Static
作用是 控制变量/函数存储方式(放到全局静态区去),生命周期(全局),作用域(当前作用域)
修饰局部变量
作用是把局部变量从栈区移动到静态存储区,作用域仍然只在语句块中,主要来保留函数调用状态的。
void counter() {
static int count = 0; // 存储在静态区
count++;
cout << count << endl;
}// 调用 counter() 3次会输出 1, 2, 3修饰全局变量或函数
作用:将全局变量/函数的作用域限制在当前文件。如果你不限制,其它文件可以extern访问内容。同样,如果多个文件都有同名全局变量,连接时候就会报错。因此相当于锁死在作用域里面,对外不可见。
// File1.cpp
static int global = 10; // 仅 File1.cpp 可见
static void func() { ... } // 仅 File1.cpp 可调用
// File2.cpp
extern int global; // 错误!无法访问 static 全局变量修饰成员变量
个人理解:就是变成全区变量但是作用域必须要类里面。
特点:所有这个类生成出来的对象都共享这一个变量,在内存中只有一个副本。生命周期从程序开始到结束。级别相当于类级别的,不依靠对象实例化,因此哪怕类还没实例化也可以用(类没实例化的话不占内存)。
class MyClass {
public:
static int count; // 声明
};
int MyClass::count = 0; // 定义并初始化
int main() {
cout << MyClass::count; // 不依靠类的实例化来实现。
MyClass obj1;
MyClass obj2;
obj1.count = 5; // 通过对象访问
cout << obj2.count; // 输出 5(共享同一副本)
cout << MyClass::count; // 直接通过类名访问
}修饰成员函数
特点:没this指针(那不是当然,和上面情况类似),只能够访问类中的静态成员(毕竟类对象都没有分配),可以直接调用(同成员函数),不能够被virtual修饰(有意义吗?)
MyClass::printCount();作用呢,可以定义一个好的工具类,封装在一起就很方便。
class MathUtils {
public:
static double PI;
static double circleArea(double radius) {
return PI * radius * radius;
}
};
double MathUtils::PI = 3.1415926535;
int main() {
cout << MathUtils::circleArea(5); // 直接调用
}Const
定义常量,保护数据不被修改。比如函数传进来一个参数,你const住保护了
int a = 10;
const int* p1 = &a; // 数据不可变(理解成 const int 类型的指针,那自然数据不可变)
int* const p2 = &a; // 指针不可变
const int* const p3 = &a; // 数据和指针均不可变还可以放在函数括号前,表示把this指针变成const this指针。因此,此时只有const类型的成员变量才可以被使用(每个函数成员变量前本来加的this-> 现在都变成 const this->。因此只有const类型才能够用,不然类型不匹配)
class MyClass {
int value;
public:
void set(int v) { value = v; } // 非 const 函数
int get() const { return value; } // const 函数
};
const MyClass obj;
obj.get(); // 正确
obj.set(10); // 错误!const 对象不能调用非 const 函数修饰类对象表示该对象只读
const MyClass obj;
obj.get(); // 正确
obj.set(10); // 错误!C和C++区别
核心理念:C面向过程,C++面向对象(封装、继承和多态)
内存管理:C(malloc,calloc)C++(new delete ,几个智能指针)
类型:C(隐式转换)C++(显式转换(但short转int这种可以不用说),还加了引用概念)
函数
| 特性 | C | C++ |
| 函数重载(overload):也可以被称为静态多态 | 不支持,因为c的名字修饰只有函数名称 | 支持,c++编译后名字修饰会含传入参数信息 |
| 名字修饰 | void func(int) → _func | void func(int) → _Z4funci函数名长4,叫func,传入int |
| 虚函数 | 无 | 有,靠这玩意实现动态多态 |
| 默认参数 | 无 | 支持默认参数(如 void func(int a = 0)),原理是,如果位置为空就压入默认值。 |
那现在也不难理解,c++ 重载时候,支持参数不同而不支持返回值不同了,原来就是名字修饰没有存信息hhhh
类
C的struct只有数据,没继承多态。更多的是数据结构实现体。而c++是一个对象实现提
C++的struct和class区别就只剩下默认访问权限了。strcut public 而 class private。
其它
STL容器,模版之类的。
C++和Java区别
c++核心理念:提供高性能、底层控制与灵活性,同时兼容 C 语言的“零开销抽象”。
Java核心理念:简化开发、强调跨平台性和安全性,通过“一次编写,到处运行”(Write Once, Run Anywhere)实现高可移植性。
| 特性 | C++ | Java |
| 内存管理 | 手动(new / delete) | 自动垃圾回收。因为所有new操作都是在堆,后台程序自动挥手。 |
| 平台依赖 | 需要针对不同的系统分别编译,因此C++最后直接把代码翻译成特定 CPU 架构的机器指令(如 x86、ARM),而不同操作系统提供的接口不同,因此需要去翻译移植。 | 编译一次,生成了字节码文件(.class),对于这个文件任何安装了JVM(java虚拟机)的都可以运行,所以本质是就是运行时候放在虚拟机里面,可见效率会滴。 |
| 多重继承 | 支持 | 只能继承一个类,但支持继承多个接口。接口interface,那你后面就要implements,标上@override |
| 系统类型与泛型 | C++模板编译时候展开,运行时候就没有开销了 | 泛型:类型擦出的“语法糖”。Java泛型在编译后会擦除类型参数,例如,List<String> 和 List<Integer> 在运行时都表现为 List(原始类型)。替换为object对象,牺牲了灵活性和运行时信息。 |
| 指针 | 有 | 无,对象即引用。赋值操作就是引用。函数参数传递会改变原来对象。 |
| 面向对象 | 部分 | 完全,除了基本数据类型之外,其余的都作为类对象 |
| 异常处理 | 可抛出任意类型(如 int、字符串),不强制捕获异常。 | 必须捕获或声明抛出的异常(如 IOException)。都继承自同一个类 |
C++和C#区别
希腊奶
C++怎么定义常量?
局部常量(除了字符串),放在栈区(有的可以直接变成立即数)
全局常量:一般直接转化成立即数了。
字符串要放在常量区,因为要分配空间用
重载,重写,隐藏
重载(overload):同一个函数名,不同作用
重写(override):虚函数继承用。
隐藏(hide):与父类重名函数,父类的就隐藏了。
构造函数
默认构造函数:来就有,
一般构造函数:重载构造函数,同一个名字,但可以传入不同参数
拷贝构造函数:把一个对象作为参数copy进来,注意深拷贝问题
注意区分以下问题
A a1 , a2;
a1 = a2; // 赋值运算
A a3 = a1;// 拷贝构造函数(沟槽的语法乱成依托)四种强制转换
static_cast
最常用安全的转换,上行转换安全(子类转成基类,基类里面一定有),下行不安全( 不会检查),因为可能有没有实现的部分。
dynamic_cast
专门用在虚函数父子类之间转化(必须有虚函数),会检查实际的指向。如果不是目标类型就返回空指针。因为要检查,所以实际性能略差。
const_cast
去除const属性
reinterpret_cast
从底层重新解释,告诉内存这块二进制你就这么解释。高危,别用
野指针和悬空指针
野指针:没有被初始化,如 int *p
悬空指针:指向已经被释放了的指针。
函数指针
是什么?一个指向函数的指针。编译时候,每个函数都有一个入口,那我直接指向这里,也可以调用函数。
首先是怎么理解 char* (*pf)(char* p) 认为是一个pf指针,指向了接收(char*)返回char*的函数。那么此时,对于这一类函数,你都可以去☞。
// 假设有一个函数,功能是处理字符串
char* fun(char* p) { ... } // 函数名叫fun
// 声明一个(函数指针pf),它能指向所有“接收char*,返回char*”的函数
char* (*pf)(char* p);
// 把pf对准(指向)fun函数
pf = fun;
// 按下遥控器的按钮——通过pf调用fun
pf(p); 那用途就有两种,调用不同函数/回调函数
void 加密A(char* data) { ... }
void 加密B(char* data) { ... }
int main() {
void (*加密方法)(char*); // 声明一个“加密遥控器”
加密方法 = 加密A; // 今天用A加密
加密方法(数据); // 实际调用加密A
加密方法 = 加密B; // 明天换B加密
加密方法(数据); // 实际调用加密B
}对于回调函数,返回我需要的特定的处理方式
// 你告诉系统:“收到消息时,调用我的处理函数”
void 收到消息时回调(void (*callback)(char*)) {
char* 消息 = 监听网络();
callback(消息); // 收到消息后,调用你提供的函数
}
// 你的处理函数
void 我的处理(char* 消息) { ... }
int main() {
收到消息时回调(我的处理); // 注册你的函数
}堆和栈
栈:编译器管理,一般保存局部变量和函数参数,编译器自动回收。
再调用函数时候,先入栈主函数下一条地址(即func执行完成后,要返回的地址),再把函数参数从右往左插入,这里是为了便于解析可变参数类型。比如下面,我最后一个压入count,那我出来的时候,就第一个出来,就知道参数啥。
#include <stdio.h>
#include <stdarg.h>
// 可变参数函数示例
void print_sum(int count, ...) {
va_list args;
va_start(args, count); // 从栈顶读取 count 之后的参数
int sum = 0;
for (int i = 0; i < count; i++) {
sum += va_arg(args, int);
}
va_end(args);
printf("Sum: %d\n", sum);
}
int main() {
print_sum(3, 10, 20, 30); // 参数入栈顺序:30 → 20 → 10 → 3
return 0;
}堆:程序员手动管理,new delete malloc free之类的去管理。内部空间是一块一块的,需要去管理。(ics手动做过)
new/delete/malloc/free
都是在堆上分配回收。new/delete是操作符(可以改构造函数/析构函数用),malloc/free是库函数(标准库提供的,改不了)
new:先malloc,再分配类型对象
delete:先析构,再free内存
为什么要有new和delete?因为malloc和free对于动态对象很难实现。而new和delete会自动调用构造和析构函数,保证初始化和析构正确性。
Volatile和extern
volatile:告诉编译器,这个值可能会被程序外其他因素意外修改,因此你不要优化或者假设稳定性。比如说要连续多次读取,你就老老实实一次次从地址读,不要从寄存器去整了
1.易变性,每一次读取都可能不同
volatile int sensor_value;
// 假设 sensor_value 是硬件传感器的实时值
int a = sensor_value; // 从内存读取
int b = sensor_value; // 再次从内存读取,而不是复用寄存器中的 a 的值2.不可优化性
volatile bool flag = false;
while (!flag) { /* 等待外部事件修改 flag */ }
// 编译器不会将 while 循环优化为 if (!flag) { while(1); }3.顺序性
volatile int a = 1;
volatile int b = 2;
a = 3; // 操作 1
b = 4; // 操作 2
// 编译器保证操作 1 在操作 2 之前执行,不会被重排。extern:告诉变量或者函数在别的地方定义,你去别处找。这样节省了一点预处理时间。同时在c++中,如果要按照c语言命名和调用规则编译,可以加入
// C 库函数声明
#ifdef __cplusplus
extern "C" {
#endif
void c_library_function();
#ifdef __cplusplus
}
#endifdefine和const
#define 是预处理指令,再预编译阶段,就直接简单的文本替换
const 是关键字,用来定义变量是常量。
类的大小
class A{};sizeof(A) = 1;//空类为1
class A{virtual func(){};} 4//虚函数,会有一个指向虚函数表的指针,因此多少个虚函数都多加4
class A{static int a; int b;} sizeof(A) = 4; //static不算
class A{func(){};}; sizeof(A) = 1; //函数在代码区,不占空间封装,继承,多态
封装:类。把客观事物变成抽象的类,调用时候只调用方法。
继承:让一个类获得另一个类能力,便于扩展
多态:同一个名字,多种不同的实现。有静态多态(重载overload)和动态多态(override)
虚函数原理
虚函数表:当一个类中有虚函数,就会为这类生成虚函数表
先举个例子
class Animal {
public:
virtual void speak() { // 基类虚函数
cout << "Animal sound" << endl;
}
};
class Dog : public Animal {
public:
void speak() override { // 派生类重写
cout << "Woof!" << endl;
}
};
int main(){
Animal* animal = new Dog();
animal->speak(); // 输出 "Woof!"
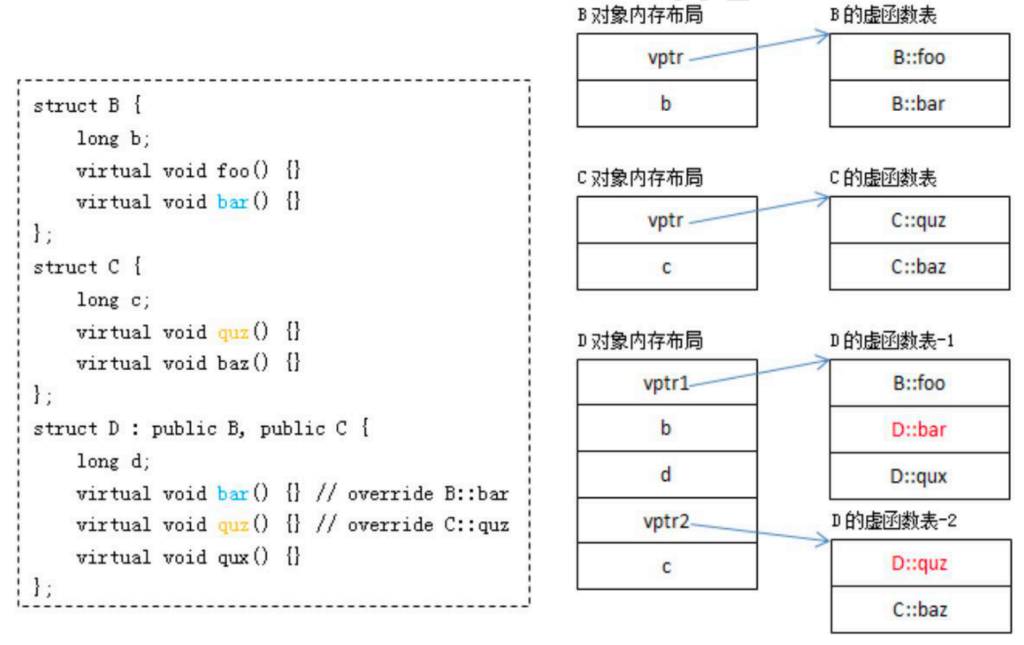
}原理是什么呢?当一个类有虚函数,就会生成一张虚函数表,指向实际类型的虚函数。派生类那就一定也有虚函数了,此时自己也就有了虚函数表。
当生成派生类对象时候,编译器检查出来有虚函数,就会为这个派生类生成虚函数指针,指向虚函数表。如果自己实现了,那么虚函数表指的就是自己实现的函数,否则就是继承下来的虚函数。
如果此时用一个基类的指针,指向一个派生类(Animal* animal = new Dog();)那么调用方法时候,虚函数指针就会指向派生类的,因此调用派生类函数。而其它非虚函数,还是animal自己的function。(如上图所示)
但是注意,如果没有virtual,那么就是你定义的类(animal)
class Base {
public:
void func() { cout << "Base"; }
int base_data = 10;
};
class Derived : public Base {
public:
void func() { cout << "Derived"; } // 隐藏基类函数
int derived_data = 20;
};
// 当编译器看到以下代码:
p->func();
// 编译器的工作:
1. 检查p的类型 → Base*
2. 在Base类中查找func()函数
3. 发现func()不是虚函数 → 执行静态绑定
4. 生成调用Base::func()的机器码在调用构造函数的时候,是先父再子对象。
在调用析构函数的时候,是先子再父的。那析构函数几乎一定要是虚函数。why?
class Animal { ~Animal(){}};
class Dog : public Animal {~Dog(){}};
int main(){
Animal* animal = new Dog();
delete animal; //此时,如果不用虚函数,编译器根本找不到最底下那个Dog,只会调用Animal的方法,这显然会有问题!。
}在继承时候,如果多继承,每个虚函数基类都会有一个虚函数表
那构造函数为什么不用虚函数?
- 虚函数机制依赖已初始化的vptr,而vptr初始化是构造函数的职责。形成一个循环悖论。
- 虚函数的本质是「对已有对象」进行功能调用(看不懂算了不看了)
纯虚函数
让你子类必须要去实现,同时这个基类变成抽象类(即自己不能够实例化),这在编译阶段就可以检查出来。
// 基类声明纯虚函数
class Base {
public:
virtual void func() = 0; // 纯虚函数(无实现)
};
// 尝试实例化基类
Base obj; // ❌ 编译错误如果你又虚函数,定义了却不去实现。那么如果实例化时候,就仍然会报错,不过是在链接阶段(编译器不清楚你是不是写别的文件了)。其实本质和你类写了方法不实现是一个道理。
// 基类声明普通虚函数但未实现
class Base {
public:
virtual void func(); // 普通虚函数(未实现)
};
// 实例化基类(合法)
Base obj; // ✅ 编译通过
// 调用未实现的虚函数
obj.func(); // ❌ 链接错误虚继承
why?因为菱形继承时候,会产生二义性
此时,如果你调用d.a,是意义不明确的。因为内存此时分布如右所示
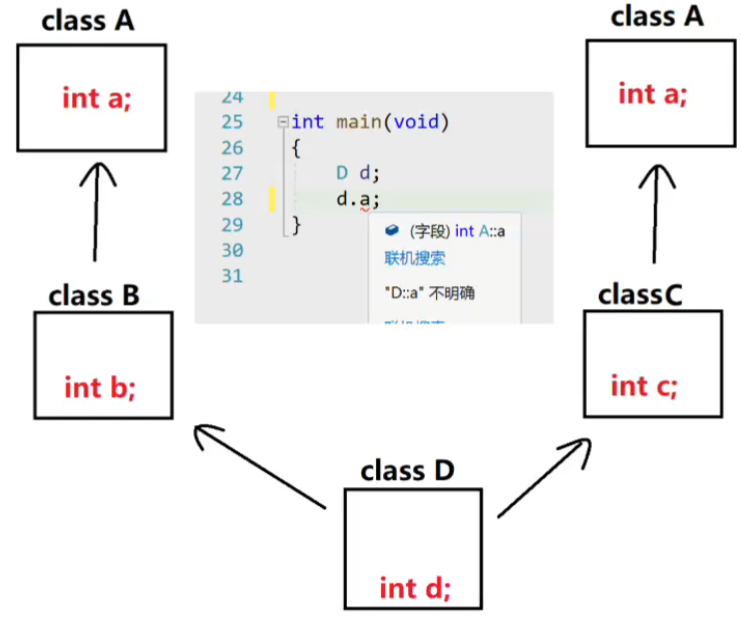
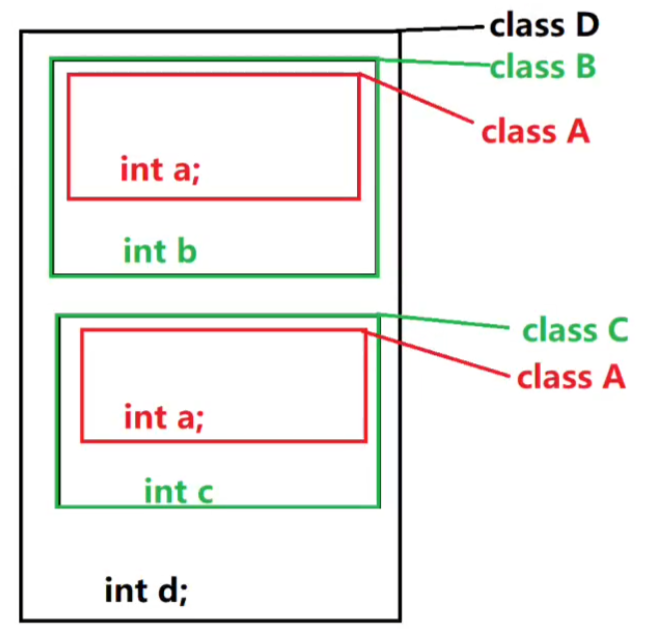
此时,你用虚继承,就可以解决,内存布局会变化。B和C虚继承了
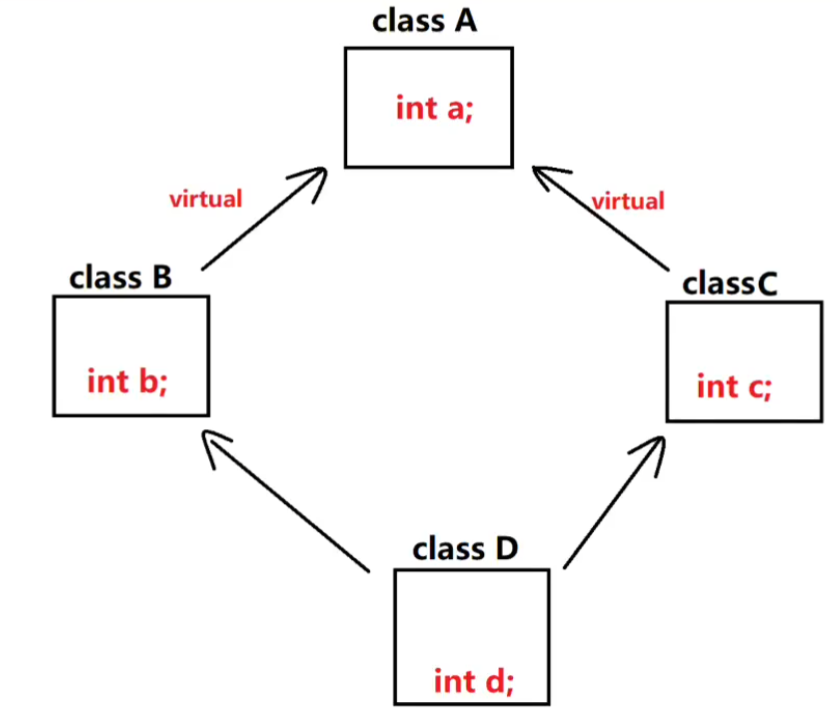
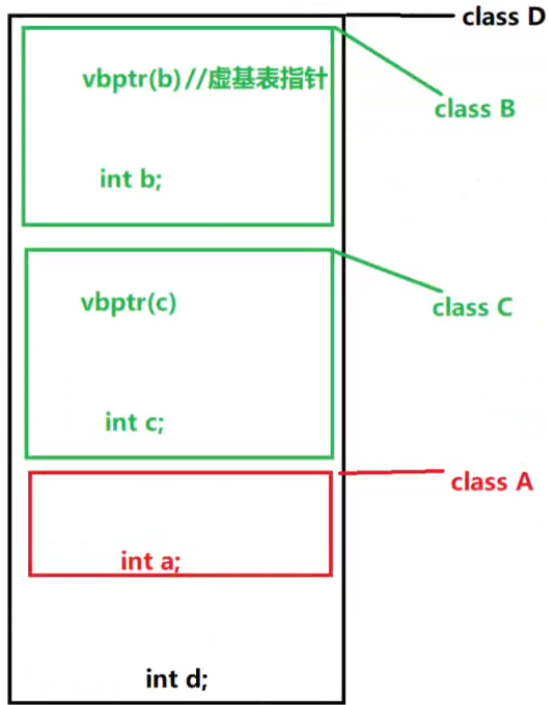
原理是,当使用虚继承时候,会用虚基表指针指向虚基表。最后,虚基类子对象是在派生类决定的,这时候就会发现继承自同一个A,那么就不用多写几份了。
静态绑定,动态绑定
虚函数动态绑定:调用func的时候,会调用到你子类的func(通过虚函数表,但虚函数表只有指针)
默认参数的静态绑定:默认参数绑定是根据静态类型决定的(因为只存了指针,没有存变量数据)
#include <iostream>
using namespace std;
class Base {
public:
virtual void func(int x = 10) { // 基类虚函数,默认参数 10
cout << "Base::func " << x << endl;
}
};
class Derived : public Base {
public:
void func(int x = 20) override { // 派生类重写虚函数,默认参数改为 20
cout << "Derived::func " << x << endl;
}
};
int main() {
Base* obj = new Derived();
obj->func(); // 实际调用的是谁的默认参数?
delete obj;
return 0;
}
Derived::func 10 // 期望是 20,但实际是基类的默认参数 10!所以,千万不要去重定义虚函数的默认参数!到最后,还是调用的基函数的,可能与你所想不一致。
深拷贝,浅拷贝
默认浅拷贝,对于指针只是复制值,导致内容没复制。这时候delete可能导致多次删除。此时就必须自己重写拷贝函数,保证安全。
什么时候会调用拷贝构造函数?
以值传递传入对象到函数,以值传递从函数返回对象,一个对象需要通过另一个对象初始化
为什么拷贝构造函数必需时引用传递,不能是值传递?
避免循环引用。你值传递时候,就会默认构造一次拷贝构造函数。
内存对齐
原则:每个成员的位置,都是自己大小的整数倍。同时整个结构体是最大成员的整数倍。
为什么快了?因为现代cpu都是一块一块读,比如一次读2,4,8,16之类的。如果你是从1开始,那你先读了0~3,不够,还要读4~7,然后还要小心翼翼的剔除前后多余的。这样做了很多没必要的操作,大大降低了性能。为了避免这种浪费,现代很多cpu遇到没对齐的数据就直接拒绝处理,这更是雪上加霜。
内存泄漏
申请了一片内存,但是用完之后没有释放。用valgrind扫出来
怎么避免?智能指针,stl容器,确保抛出异常时候依然正常释放
二叉树
二叉树:每个节点最多俩子节点
二叉搜索树:左节点<根节点<右节点
二叉平衡树:左右子树高度差不要过高。
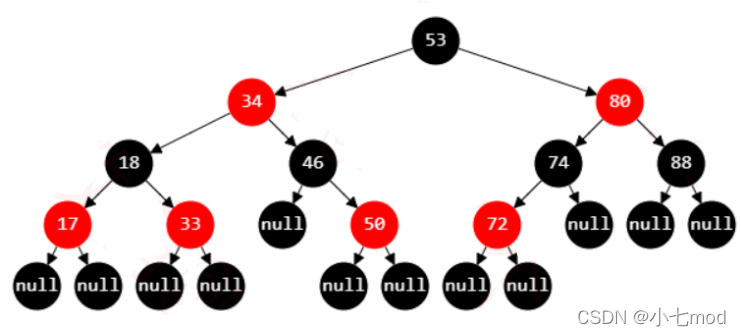
红黑树
1.根节点黑 2.叶子节点黑(外部) 3.红节点不连红节点 4.从根节点,到任意叶子结点 5.插入时候默认是红的
插入原则:看叔叔脸色(具体忘了)
define,const,typedef,inline
#define:在代码编译之前的文本替换
typedef:在编译器解析没问题,把它视为真正的类型。
inline:给编译器一个建议,把这段函数嵌入过去
typedef int* INT_PTR;
INT_PTR a, b; // a 和 b 都是 int* 类型(符合预期)
using FuncPtr = int(*)(int, int); // 等价于 typedef int(*FuncPtr)(int, int);预处理,编译,汇编,链接(ciso)
把一段高级语言编程二进制代码需要4个阶段:预处理,编译,汇编,链接
| 阶段 | 输入 | 输出 | 核心任务 | 特点: |
| 预处理 | .c | .i | 处理全部#任务 1.展开头文件#include<stdio.h>,直接插入本文件 2.宏替换 ,#define PI 3.14之类直接文本替换 3.条件编译#ifdef和#ifndef等判断是否保留 | 纯文本替换 |
| 编译阶段 | .i | .s | 把高级语言翻译成汇编。 1.检查语法,语义是否正确 2.对代码简单优化 3.生成汇编代码(不同CPU架构不同) | 翻译成汇编 |
| 汇编阶段 | .s | .o | 把汇编代码变成机器指令(二进制) 1.把每一条汇编语句变成一条机器码 2.生成机器指令,数据段,符号表(不知道空着) 汇编代码 call puts 会被翻译为二进制指令 E8 00 00 00 00(假设 puts 的地址暂时未确定)。 | 生成二进制,但地址未最终确定 |
| 链接阶段 | .o .a [库文件] | .out/.exe | 合并多个目标文件,解析符号地址 1.找到所有未定义的符号(如 printf)的具体地址。 | 链接可以是静态链接(库代码直接嵌入可执行文件) 或动态链接(运行时加载库)。 |
如果头文件的内容没有在.cpp中实现,会怎样?报错,但是在链接阶段,因为链接阶段找不到具体的实现。
动态编译和静态编译
- 静态编译:把需要的库文件直接打包进最终的可执行文件
- 好处:简单。
坏处:文件体积大(哪怕只需一个函数却要整个库),更新要重新编译整个文件,多程序浪费
- 好处:简单。
- 动态编译:只需要记录引用的信息,运行的时候动态加载
- 好处:文件体积小,多程序共享库,库更新不用重新编译主程序
- 坏处:需要正确版本的运行库去解释,环境部署依赖库(python)
静态链接和动态链接
- 静态链接
- 链接时间:编译时
- 包含内容:把lib中代码完整的复制到可执行文件
- 更新:修改整个程序
- 动态链接
- 链接时间:运行时
- 包含内容:记录文件模块(DDL)的函数位置信息
- 更新:更换DDL就更换了功能
动态联编与静态联编
- 静态联编(早绑定)
- 编译时候绑定,根据指针/引用的类型声明
- 特点:效率高(运行时无开销),但不太灵活
class Base { void func(); };
class Derived : public Base { void func(); };
Base* obj = new Derived();
obj->func(); // 调用Base::func(静态绑定)- 动态联编(晚绑定)
- 运行时绑定(通过虚函数表去看)
- 灵活,但有开销
class Base { virtual void func(); };
class Derived : public Base { void func() override; };
Base* obj = new Derived();
obj->func(); // 调用Derived::func(动态绑定)友元
是一种打破类封装的机制,允许其他类或函数访问当前类的私有(private)或者被保护(protected)成员
class Box {
private:
int width;
public:
Box(int w) : width(w) {}
// 声明友元函数
friend void printWidth(Box box);
};
// 友元函数可以访问 Box 的私有成员
void printWidth(Box box) {
cout << "Width: " << box.width << endl;
}
int main() {
Box b(10);
printWidth(b); // 输出: Width: 10
}类和数据抽象
类与类关系:
has-A:B类用了A类作为变量,声明周期相同
use-A:B类用了A类作为返回值或者函数变量。声明周期临时
is-A:本质就是父子类的层次关系
继承特点:
子类拥有父类全部属性方法,子类可以拥有父类没有的方法,子类对象可以当做父类对象使用。
组合:内嵌其它类对象作为自己成员
什么时候需要成员初始化列表?
什么是初始化列表?
class MyClass {
public:
// 初始化列表语法
MyClass(int a, int b) : m_a(a), m_b(b) {
// 构造函数体(此时成员已初始化完毕)
}
private:
int m_a;
int m_b;
};这是在对象创建时,直接初始化成员变量。
为什么需要?
总结:对于必须初始化的变量(const,引用),没有默认构造参数的,在对象创建之初就给他分配好。
初始化const
class Circle {
public:
Circle(double r) : PI(3.14159), radius(r) {} // ✅必须用初始化列表
private:
const double PI; // const成员
double radius;
};初始化引用
引用必须要初始化时候绑定,也不能更改
class Student {
public:
Student(int& id) : ref_id(id) {} // ✅必须用初始化列表
private:
int& ref_id; // 引用成员
};调用基类的有参构造函数
如果基类没有默认构造函数,那就必须要显示调用(其它时候编译器隐示的调用了)
class Base {
public:
Base(int x) { /*...*/ }
};
class Derived : public Base {
public:
Derived(int a) : Base(a) { /*...*/ } // ✅显式调用基类构造函数
};初始化成员对象
成员对象类没有默认构造函数
执行顺序
成员变量的初始化顺序,由类的声明顺序决定(与初始化列表无关)。
基类构造函数先于派生类构造成员初始化
class Example {
public:
Example(int x) : b(x), a(b) {} // ❌危险!a先初始化,但此时b未初始化
private:
int a; // 先声明
int b; // 后声明
};与构造函数体赋值对比
| 方式 | 初始化列表 | 构造函数体内赋值 |
| 本质 | 直接初始化(调用构造函数) | 先默认构造,再赋值 |
| 适用对象 | 所有对象 | 非const,引用 |
| 效率 | 高效率(避免二次操作) | 低效率(构造+赋值是两步) |
STL容器
| 底层数据结构 | 特性 | 迭代器 | 数据结构 | |
| vector | 动态数组 | 1.连续存储,随机访问o1 2.动态扩展,按指数分配空间 | 普通指针可以完成 | 三个指针:start(当前使用空间头)finish(当前使用空间尾)end_of_storage(可用空间尾) |
| list | 双向链表 | 1.非连续存储,双向链表存储 2.根据实际节点分配内存 | BidirectionalIterator 支持++和–,但无法随机跳跃 | 一个指针指向头结点 |
| deque | 双端队列 | 1.分段连续存储,逻辑上连续, 物理上分段,支持双向动态扩容。 即,可以O(1)随机访问 | RandomAccessIterator 包含四个指针 cur,first,last,node | start和finish迭代器分别指向守卫缓冲区 |
| stack | 栈 | 1.底层容器默认deque 2.先进后出 | 依赖底层容器 | |
| queue | 队列 | 1.底层容器默认deque 2.先进先出 | 依赖底层容器 | |
| priority_queue | 优先队列 | 1.容器默认vector 2.本质是堆 | 无直接访问 |
Vector的push_back和emplace_back
push_back():需要先就地构造对象,然后拷贝,然后再释放原有对象,效率比较低
emplace_back():直接在容器内构造对象,就用这种+强制类型转换
map和set区别
联系:底层都是红黑树
| 特性 | map | set |
|---|---|---|
| 存储内容 | 键值对(key-value) | 单个键(key) |
| 修改键(key) | ❌ 不可修改(影响排序) | ❌ 不可修改(直接是元素本身) |
| 修改值(value) | ✅ 可修改(不影响排序) | 无值(元素即键) |
| 下标操作 | ✅ 支持(按 key 查找或插入) | ❌ 不支持 |
| 迭代器行为 | 键只读,值可修改 | 迭代器完全只读(元素不可修改) |
对于map中,如果访问不存在的,会返回一个默认值。
迭代器
是STL容器的通用指针
为什么需要?因为如果每种容器都用自己的遍历方式,写一个通用的“查找算法”需要针对不同容器写多份代码。迭代器的核心价值就是统一所有容器的遍历接口!
int arr[5] = {1,2,3,4,5}; // 数组
list<int> myList = {1,2,3,4,5}; // 链表有些容器支持随机访问,比如vector,deque,
有些可以前后访问,比如list,set,map。用++,–往前后
其本质不是指针,但表现得很像指针。你可以用指针的方式去访问比如*,->等。但本质是类对象,只是重载了操作符。
迭代器失效
迭代器失效:指向元素的指针可能因为内部结构变化,指向无效的数据。
vector<int> v = {1, 2, 3};
auto it = v.begin() + 1; // 指向 2
v.push_back(4); // 可能导致扩容
// 此时 it 可能指向无效内存,访问 *it 会导致未定义行为STL删除元素
vector和deque,删除后后面所有元素迭代器都失效了,但是会往前一个,earse返回下一个有效迭代器
比如s.begin()+2,后面肯定用不了了
map set,使用earse后,这个迭代器就失效了,不影响其它的。需要你提前记录下一个有效的迭代器。
resize和reserve区别
reserve:预留容量,避免多次动态扩容。不会删元素
resize:直接修改元素数量,使当前vector大小为size。若n>size,则初始化0,n<size,则多余的部分被析构。
模板类的实现
在编译器处理模板时候,会分为两步,一步检查模板本身有没有问题,第二是根据类型生成实际代码
第一次编译(模板代码检查):此时编译器只是“记住”这个模板的存在,但不会生成任何实际函数。
// 模板声明和定义(在头文件中)
template <typename T>
void mySwap(T& a, T& b) { // 第一次编译:检查语法
T tmp = a;
a = b;
b = tmp;
}第二次编译(实例化代码生成):根据实际类型如int等,生成模板函数
// 实例化生成的具体代码(编译器自动生成)
void mySwap(int& a, int& b) {
int tmp = a;
a = b;
b = tmp;
}
++i和i++
++i不会有临时变量。i++会产生临时变量
大小端怎么检测
int个数,强制转成byte*,看看第一个是啥
int(*p)[10] int *p[10] int *f(int i) int(*f)(int i) 的区别
*结合优先度很低,如果结合就表示指向…..的指针。第一个为指向数组的指针,第二个是含有10个指针的数组,第三个是返回值为int *的指针,第四个是函数指针,指向接收int返回int的函数
进程线程协程
进程:操作系统资源分配基本单位,拥有独立的内存空间。操作系统会以进程为单位分配系统资源(内存,时间片等)
线程:进程之间共享同一进程资源(内存,文件句柄等),创建开销比较少。每个线程有自己的调用栈,适合CPU密集型(因为在cpu上可能真的多核在跑)
协程:轻量级线程,在单线程内异步切换。所有协程共享栈,因此切换时会保存和恢复,适合需要io密集型(本质上就还在一个线程里,只是切换得快,这样懒得去等了)
函数调用开销
- 传参开销,值传递复制开销,引用传递开销
- 函数的调用栈:保存调用者上下文,分配栈帧,回复上下文
- 返回值开销:新建对象
- 缓存失效:丧失了局部性,新上来页把原先的挤掉了
i++是否线程安全?
不安全,因为不是原子操作。涉及到取到原数,加,再赋值回去。
函数都放在哪里
代码段中,不占用类的大小。虚函数表放在程序只读数据段+-
左值与右值和移动语义
左值:有地址,可以取地址,出现在等号左侧。
右值:通常没有地址,存储在寄存器或者临时变量。不能&,字面量表达式结果都是右值
右值引用时候,比如说 int && a = 10; 10一般没有地址,那怎么办呢,那就把10放在栈上(分配临时空间),然后a变量指向这个数(临时变量)。
纯右值:一些数据啥的,比如说10,1.1,bool之类的
move:把左值变为右值。底层到汇编来说,和你直接int &b = a;是一样的,都是起了一个别名。那有什么作用呢?目的就是为了标记这个数现在是右值了,编译器要做右值有关的事情了,比如触发移动构造,避免深拷贝。
int a = 10;
const int &&c = move(a);什么意思呢?比如说一个string,你赋值a = b,那默认就是深拷贝,每个都有一个数据,那就造成了资源的浪费。对于一个实现的很好的类也是如此,你会深拷贝数据。有时候我们不需要,就只是想指向这唯一一个数据避免浪费,就有了move。元数据内容也就为空了。
string str1 = "hello";
string str2 = move(str1);
cout << "str1:" << str1 << endl; // 为空
cout << "str2:" << str2 << endl; // hello,直接把数据偷走,即交出所有权。至于底层实现,那就更直接了。就是static_cast强制转换为右值类型。
模板常见用途
对于一些数据结构,可以通用的实现。
编译时长因素
- 最直接的,代码量。源文件数量越多,行数越多,编译时间越长。
- 头文件或者重复包含,或者用了很多inline,也会导致这个问题。
- 模板类,为每个新实例(int double之类的)都会生成新的符号(函数,类名),编译器需要维护实例化信息。
- 编译器,不同的优化策略,不同的优化级别(-O2 -O3)
C++11新特性
空指针 nullptr
nullptr专门用来表示空指针,类型是 std::nullptr_t,可以被隐式转换为任何指针类型(如 int*、char* 等),但不能够转换为整数
NULL是C语言留下来的宏,本质就是0或(void*)0,要看编译器
这样可以避免歧义,保证类型安全。比如下面,你具体就不知道调用到哪里去了,很危险。
void func(int*);
void func(double);
func(NULL); // 可能调用 func(double)(如果 NULL 是 0)Lambda
本质是匿名函数。
[捕获列表] (参数列表) -> 返回类型 {
函数体
};- 捕获列表:定义lambda对外部变量的可见性
- 参数列表:就是函数参数,一样的东西
- 返回类型:可省略,即 ->返回类型这一块一起省略,编译器可以推断出来
- 函数体:具体实现的逻辑
常见几个用途:1.STL比较函数 2.回调函数 3.闭包
// STL比较器
vector<int> nums = {3, 1, 4, 1, 5};
sort(nums.begin(), nums.end(), [](const int &a,const int &b) {
return a > b; // 降序排序
});
//回调函数
void processData(const vector<int>& data, function<void(int)> callback) {
for (auto num : data) {
callback(num);
}
}
processData(nums, [](int num) {
cout << num * 2 << " ";
});
//闭包(保存状态)
auto makeCounter = [](int start) {
return [start]() mutable {
return start++;
};
};
auto counter = makeCounter(5);
cout << counter(); // 5
cout << counter(); // 6右值引用
那先得搞明白什么是左,什么是右
右值:临时的不可取地址的值,比如说3,“114514”这种。
左值:可以取地址,有名字,可以持久化状态的对象。
int x = 5; // x 是左值
int* p = &x; // 可以取地址
int y = x + 3; // x+3 是右值(临时结果)
string s = "hello"; // "hello" 是右值(字面量)左值引用你就直接&完事了,所以一般只能引用左值,对于常量
int &a = 7;// 错误
const int &a = 7;// 对那为什么需要右值引用呢?对于以下案例,上面那个X x3 = make_x(),你需要有3次构造。分别是局部变量x1,作为返回值的临时变量,最后赋值过来给x3构造。
class X{ ////;} //省略具体
X make_x(){
X x1;
return x1;
}
int main(){
// X x3 = make_x()
X && x2 = make_x();
x2.func();
}而使用右值,你可以减少一次,最后一次赋值那一步不用赋值,直接用它返回的那个。
编译时常量
const是运行时常量,constexpr是编译时常量,强制编译期求值。
constexpr int N = 5; // N 是编译期常量
int arr[N]; // 合法:编译器知道 N 的值
constexpr int computeSize() { return 5; } // 编译期函数
constexpr int M = computeSize(); // 合法:M 是编译期常量
int arr[M]; // 合法因此const一般效率会低些,因为运行时候才带入(但如果简单常量编译器可能在编译时候优化了),同时也支持函数,也检查了类型(毕竟编译器就可以发现问题,保证了类型安全)
类型推导
auto:忽略引用,和顶层的const和&
auto x = 5; // int
auto y = 3.14; // double
auto& ref = x; // int&
const auto c = x; // const int
const int d = 1;
auto f = d; // int,忽视掉了const
const int* p = &x;
auto p2 = p; // const int*(保留底层 const)推导表达式的精确类型,包括引用和顶层 const。当然还是比较聪明的,对于临时产生的,比如说0,x+0这种纯右值,就不会给你变成int && ,而是int。而你把右值引用过来,那就是正常的int &&。
int x = 5;
const int& rx = x;
decltype(x) a = x; // int
decltype(x + 0) a1 =x //int
decltype(rx) b = x; // const int&
decltype((x)) c = x; // int&(括号导致推导为引用,(x)是左值表达式)
class A {
xxx;
};
A a;
auto c = std::move(a); // c是将亡值
auto d = static_cast<A&&>(a); // d是将亡值
decltype(c) // A &&哈希表
| 容器类型 | 是否存储键值对 | 是否允许重复键 | 底层实现 | 查询复杂度(平均) |
|---|---|---|---|---|
std::unordered_set | 否(仅键) | 否 | 哈希表 | O(1) |
std::unordered_multiset | 否(仅键) | 是 | 哈希表 | O(1) |
std::unordered_map | 是(键值对) | 否 | 哈希表 | O(1) |
std::unordered_multimap | 是(键值对) | 是 | 哈希表 | O(1) |
mult允许多个重复键,因此,你可以查出全部等于这个值的
std::unordered_multimap<std::string, int> multi_scores;
multi_scores.insert({"Alice", 90});
multi_scores.insert({"Alice", 95}); // 允许重复键
// 查找所有 "Alice" 的分数
auto range = multi_scores.equal_range("Alice");
for (auto it = range.first; it != range.second; ++it) {
std::cout << it->second << std::endl; // 输出 90 和 95
}底层就是桶,映射到一个桶后面链表或者红黑树。
锁
- 自旋锁:while循环自旋等待。
- 好处反应快,简单,不需要上下文切换。坏处吃cpu资源
- 互斥锁:如果锁被占用,就会把这个资源挂起
- 好处是节省cpu资源,但是为了记录这个挂起状态也会消耗cpu资源
- 读写锁:读都可以读,但写只有一个可以写
- 信号量:多个可以进入资源,灵活多变
在c++里面
| 锁类型 | 核心特性 | 性能开销 | 适用场景 |
|---|---|---|---|
std::mutex | 最基础的互斥锁,不可重入,不支持超时。 | 低 | 简单的独占访问(需手动管理生命周期)。 |
std::lock_guard | 简单的 RAII 锁,构造时加锁,析构时解锁。 | 极低 | 作用域内的简单互斥访问(无需手动解锁)。 |
std::unique_lock | 支持延迟加锁、手动解锁、条件变量、所有权转移。 | 中 | 需要灵活控制锁的场景(如条件变量)。 |