很喜欢一段话,来自选课社区,部分内容修改
课程内容:大概可以理解为一些软件工程plus+一些过时没用的东西。
上课自由度:chm不怎么管出勤,但多次表示有计入考勤的冲动;wd经典每节课上传jbox签到。
考核标准:
(1) chm部分占比75%,2次个人作业,1次小组作业,分别是根据给出的业务画一些UML活动图,根据给出的业务制作Petri网(课上要讲的新东西),基于RPA提取发票信息(这RPA真的难用,python全做完然后谎称用的RPA比较合适(不是),最后基本都是调用腾讯阿里API)。每次作业后会直接在课堂上汇报答辩,每个人会轮到一次。
(2) wd部分占比25%,1次读书读后感(没用的老古董),2次小组作业(都要做pre,一个是阅读一个讲数据库设计的书做ppt,一个是卷一些没用但很难写的文档)。
(3) 期末考试,wd相当于透题,两道问答题;chm要画一些UML,类图,Petri网,数据流分析。在后半学期任务量比较大。授课质量:读ppt,都是些古老过时的知识,个人感觉没啥用。
查这门课评价的应该有很多对选方向有疑问的同学吧,我只说一下个人感受,非常主观,慎重参考,如有反对,你说得对:
- 想学到大数据、AI等相关知识的同学:快跑。这方向的三门课,一门是没什么用且陈旧的意义不明课,一门是过时且走马观花无实际意义的听名字很好但实际依托课,一门是只有些理论没有示例demo且任务量大的所谓方向收口课。实际体验下来,学到的东西很有限,只能算是得到了一些科普性的拓展。想学这些知识的不如找几本书、几篇博客、几个项目去看一看,课上听不到任何有价值有深度的内容。
- 觉得这个方向轻松想要混日子的同学:快跑。wd相关的作业任务量又大又没意义,chm相关的作业意义不明不过任务量一般,其他老师相关的作业则是造火箭。或许“轻松”来源于上课睡觉或者上课做自己的事情?
- 觉得这个方向对就业有帮助的同学:快跑。课上内容深度不足(看几篇博客就能学到的东西能帮你找到工作就怪了),项目经历零增长,不如自己找几个项目看看。想就业的同学可以找rr好好聊聊,比纠结方向有用多了。
- 推荐哪些同学来:
(1) 决定完全不考虑另外两个方向的同学。
(2) 非常想要和这方向有关的实验室搭上关系的同学。
(3) 想要一整年上课睡大觉或者做自己事情的同学。
(4) 喜欢吃史的同学。
其他同学,能劝一个是一个,有点犹豫的都别来,你的犹豫源于信息的极度缺乏,你的期待源于方向名称和课程名称的“欺诈”,几乎必然会在了解实情之后感到后悔。总结:能劝一个是一个,快跑。
类图要点分析角度:
- 正确性
- 关系为什么这样是合理的(参考下面黄色内容)
- 范式化1-3-BC-4-5;反范式(你要是遍历比join还快你分什么表呢)
- 1范式:原子性 2泛式:依赖主键 3泛式:不存在传递依赖 反泛式:不按前面来
- 属于什么CDM(E-R)
- 概念数据模型-由矩形实体、菱形联系和椭圆属性组成。这是实体关系模型 (Entity-Relationship model)。
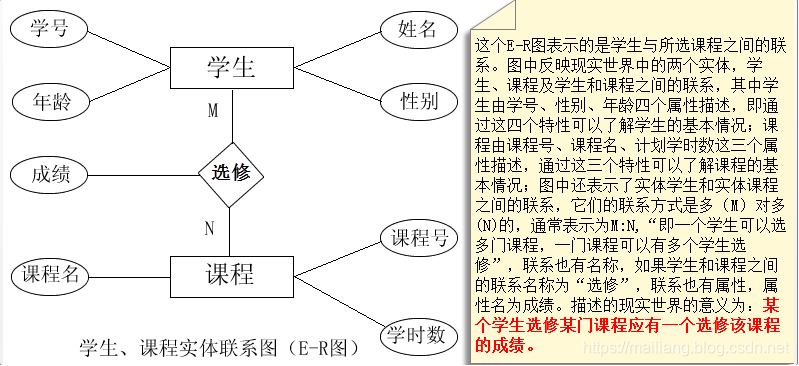
- LDM逻辑数据模型-实体包括属性
- 反映的是系统分析设计人员对数据存储的观点,是对概念模型的 进一步分解和细化。
直接连的添加。一对一的添加,一对多的在多的加,多对多的添加新的关系。
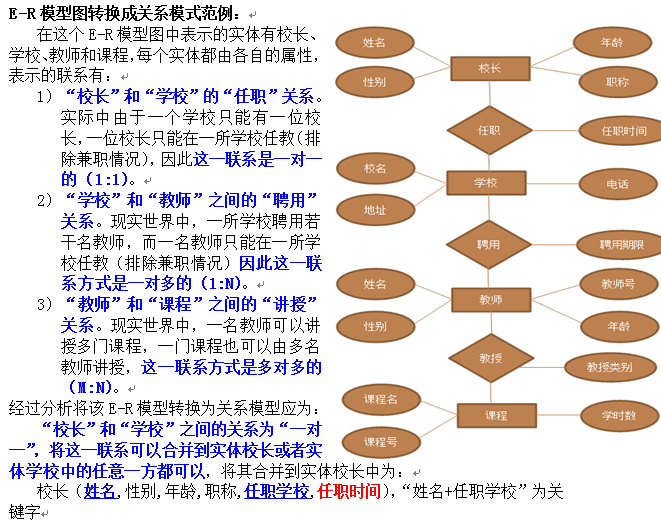

- /PDM物理数据模型-落在数据库上
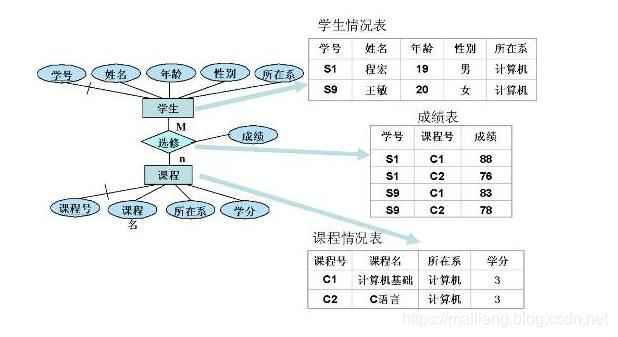
- 有没有基于“行业数据模板的数据模型”进行设计
- 使用了主题数据库进行数据规划
- 使用了信息资源管理基础标准
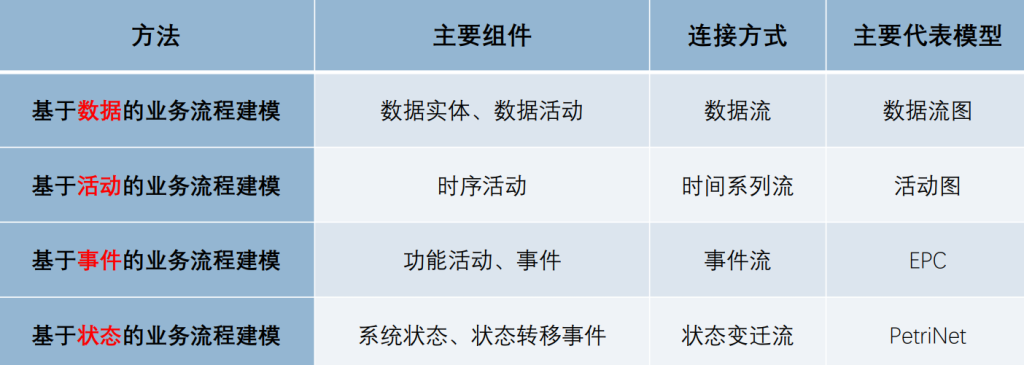
流程建模
表格形式列出任务(动词+名词)、资源、对应关系;10分至少10个活动
基于活动
本质是时序,按照从早到晚。主要包括:业务任务划分,软件功能结构设计,面向执行的活动系列以 及控制逻辑的描述 。
带泳道的UML图
对象活动的顺序关系所遵循的规则
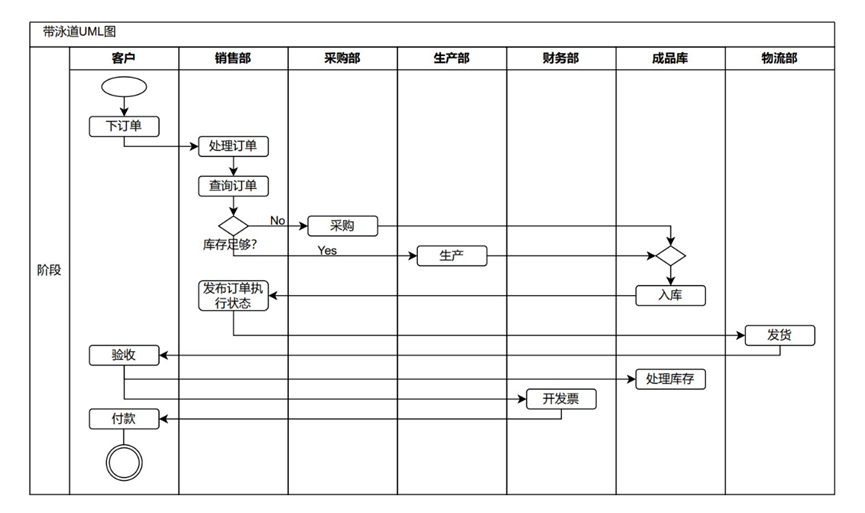
角色行为图RAD
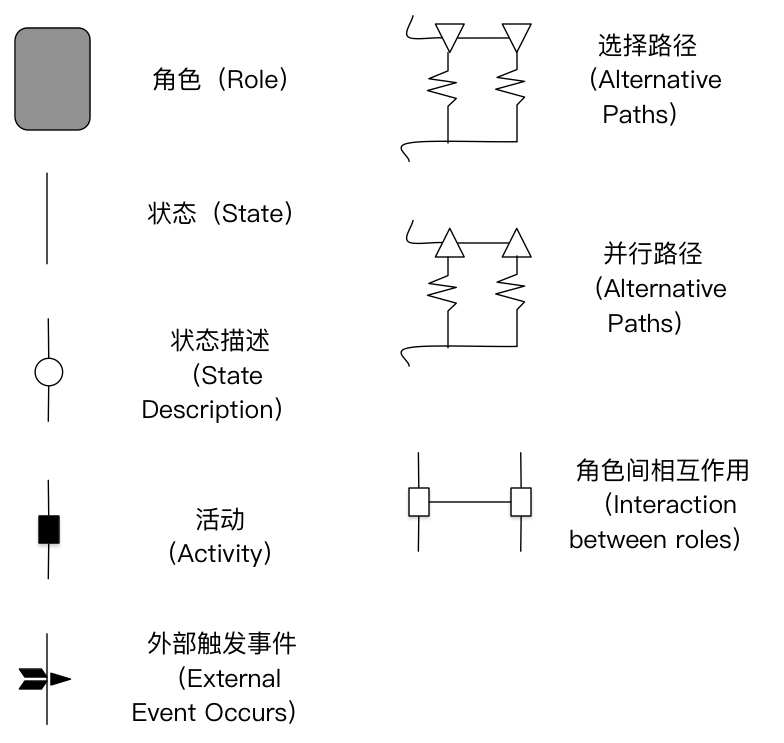
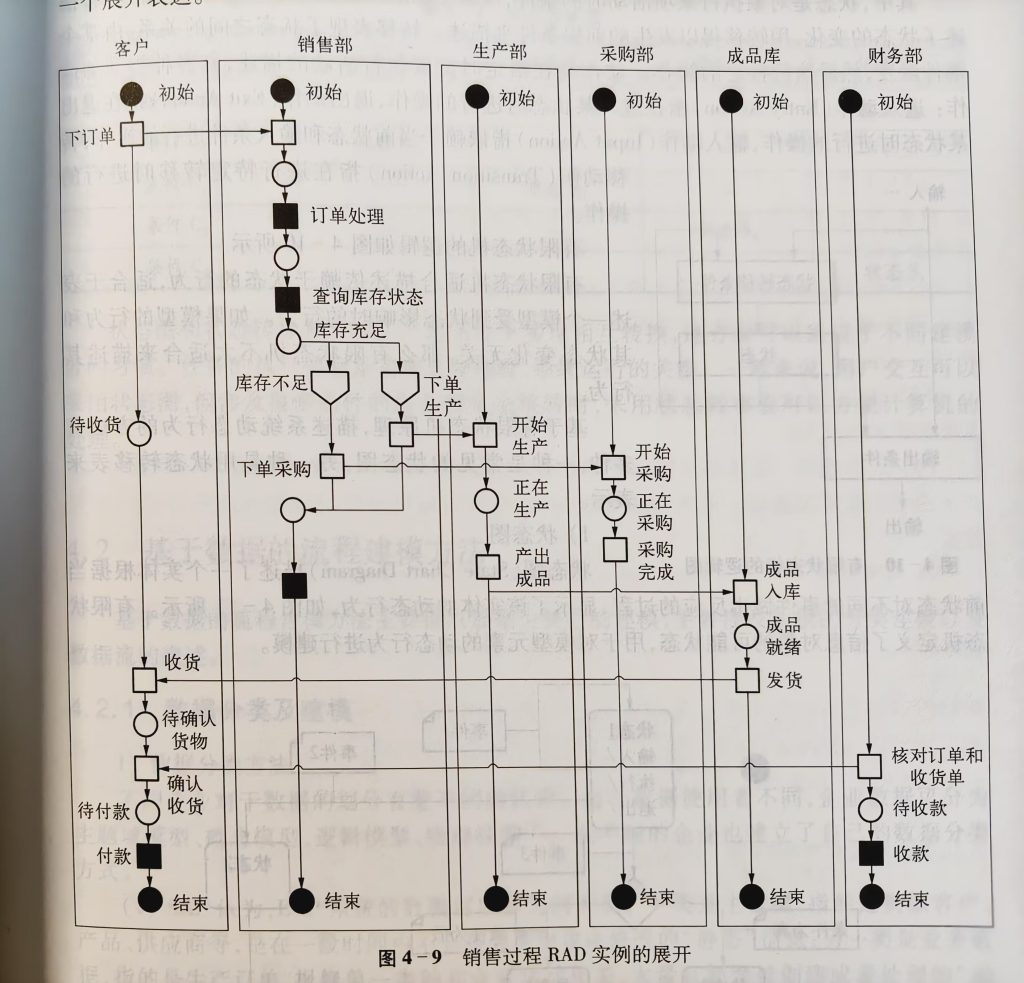
评价:角色交互清晰明了,但会使得表变复杂,同时不支持模型分解(只适合总览)
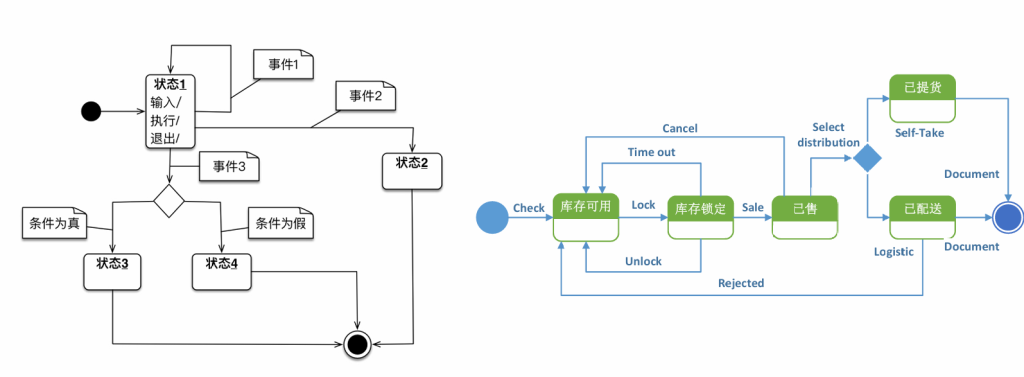
状态图
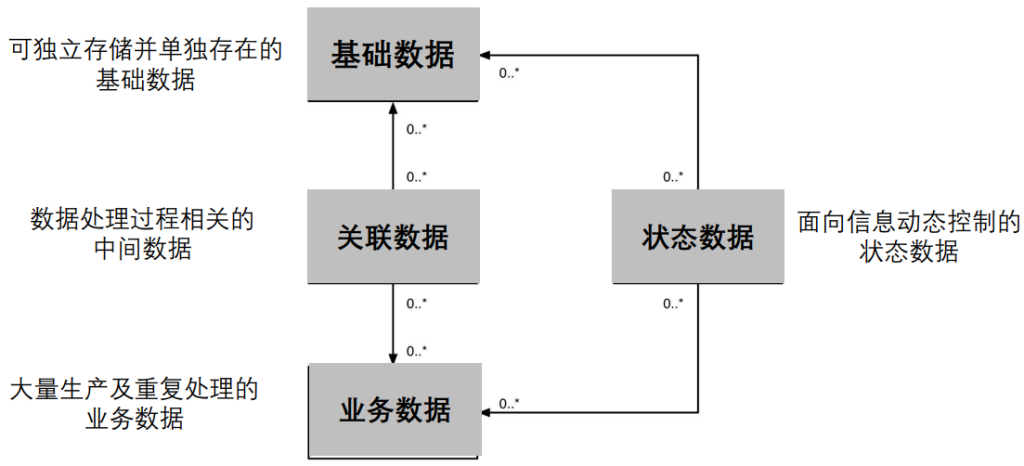
基于数据
- 基础数据(主数据):主要是相对稳定、可以在公共范围内重用的基础数据,可独立存储并单独存在,主要的操作可以分为只读不写,以及单独的增删权限等。
- 业务数据:是大量生产及重复处理的业务数据。
- 状态数据:面向流程类应用的信息控制所建立的数据,主要体现为主数据或者事务数据的动态状态变化。
- 元数据:数据管理相关的数据。
- 非结构化数据:模型、视频、语音等多模态数据,在大数据时代越来越多。
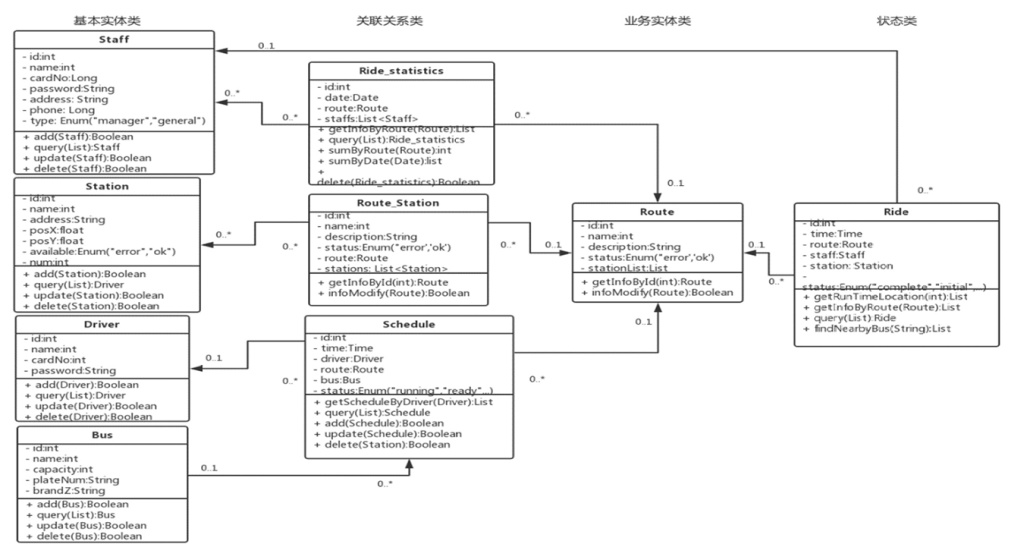
乘客、站点、司机和车辆被抽象为一些基本实体,而面向运行过程中的调度、计数、路线等抽象为业务实体或关联实体。
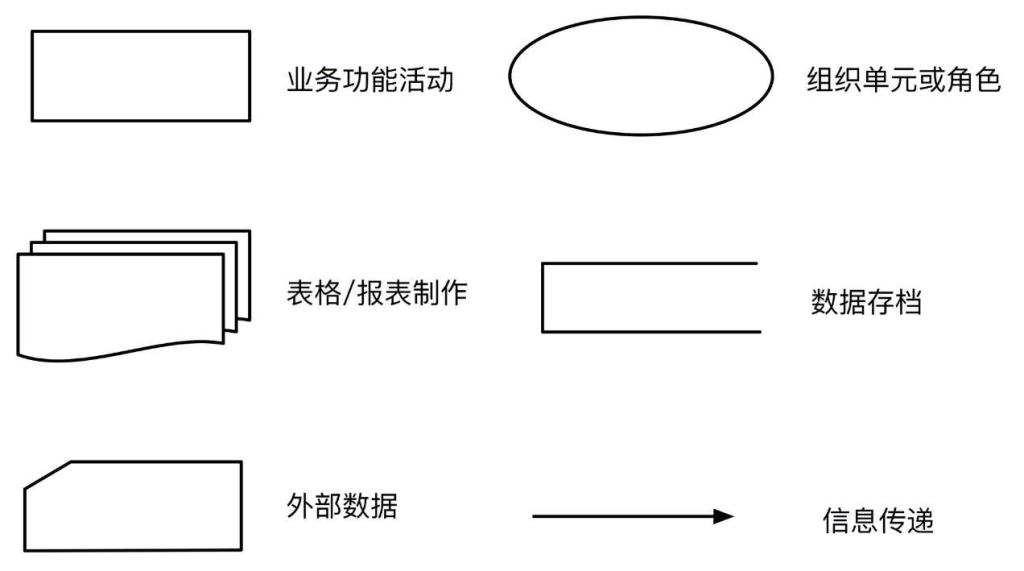
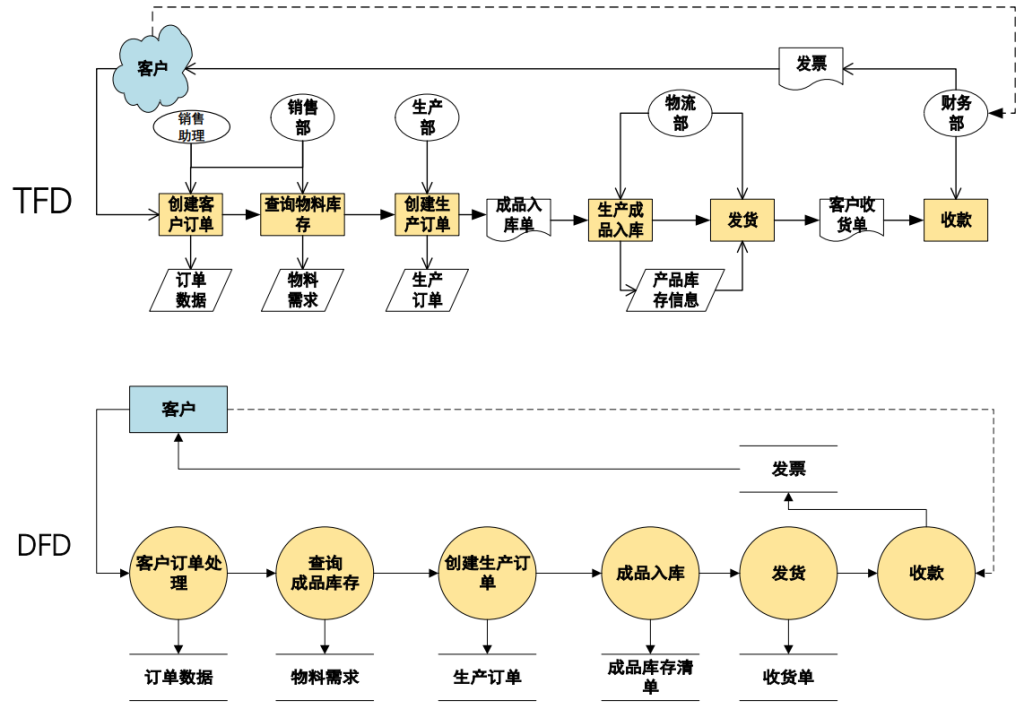
- TFD(业务流程图)和 DFD(数据流图) 都是描述业务数据处理过程的图形建模方法。
- 从描述的重点来看,TFD 强调业务过程中每一项处理活动和具体业务部门的关系。而 DFD 更注重描述业务内数据间的关系及业务的“系统”特征,标识业务通过外部实体与其环境交换信息。
- 从使用者的角度来看,用 TFD 描述企业各项业务的数据处理过程更容易与用户进行交流。DFD 较 TFD 抽象,描述的是业务处理过程的数据处理模式,但难于描述系统的控制流。
基于事件
EPC
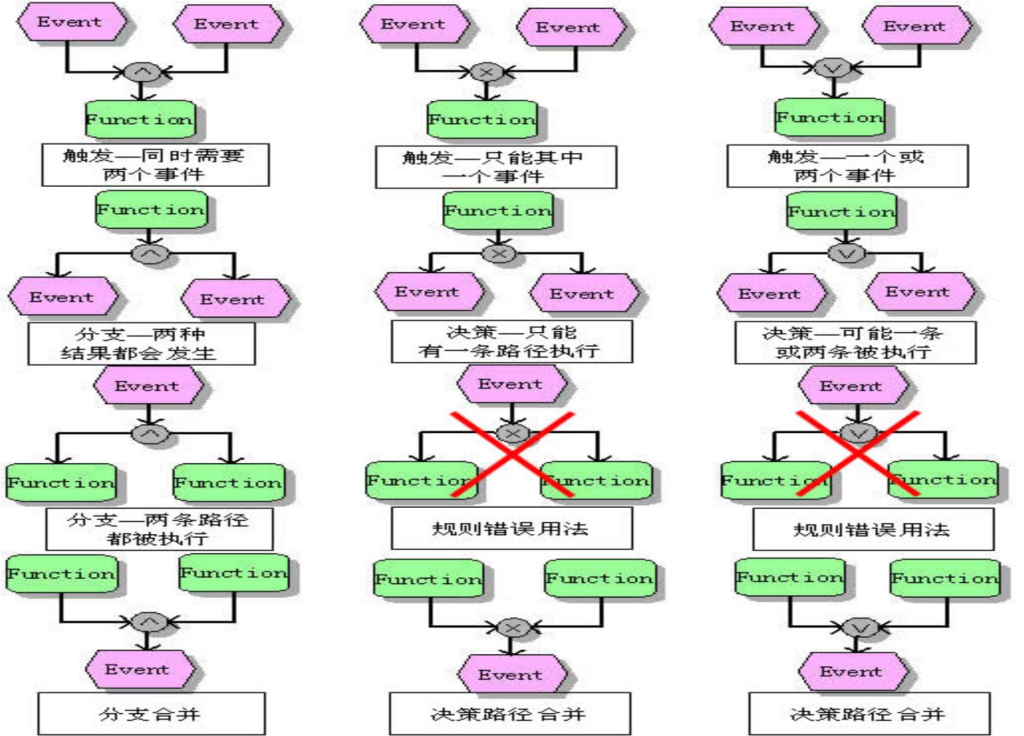
基于状态
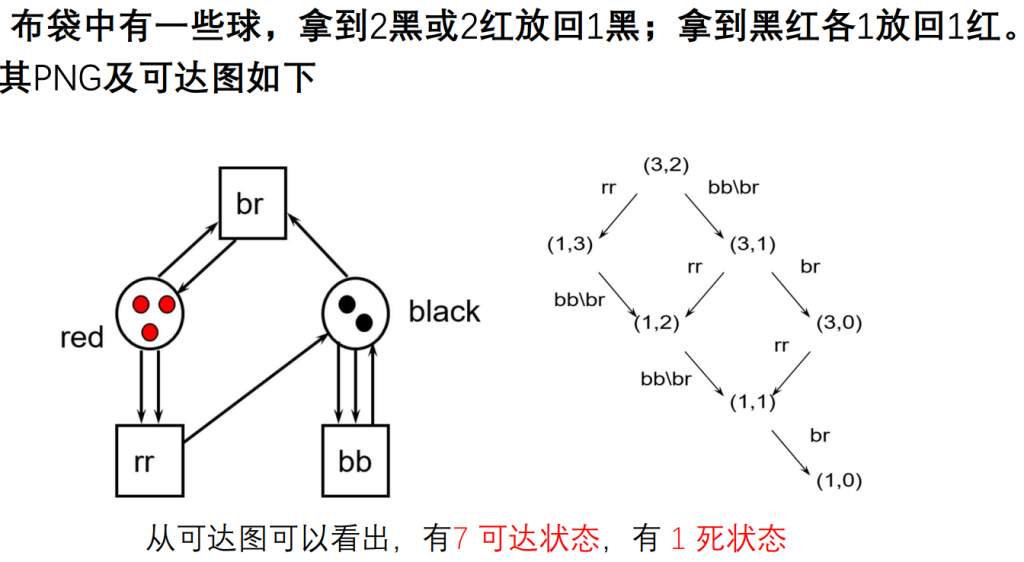
Petri
- 库所(Place)圆形节点,代表状态
- 转移(Transition)方形节点,代表活动动作/转换
- 连接(Connection)是库所和转移之间的有向边,具有方向,用有向弧表示。
- 托肯(Token)是库所中的动态对象,可以从一个库所移动到另一个库所,用实 心小圆点表示。
规则
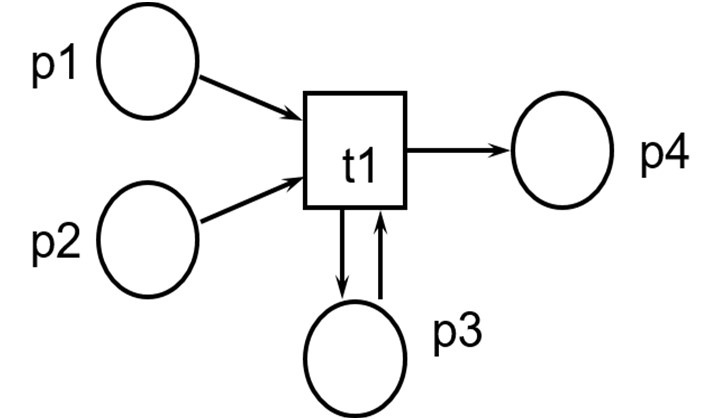
t1具有三个输入库所 (p1,p2 , p3) 和两个输出库所 (p3 , p4);库所p3既是t1的输入库所又是它的输出库所
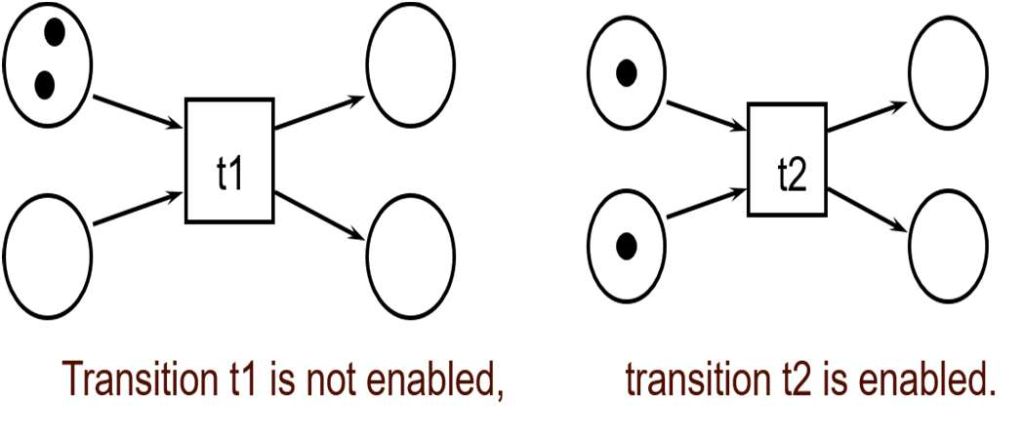
转移的使能条件:如果输入库所都包含了托肯,那么转移就被激活
一个库所链接多个转移,随便走一个;一个转移连多个库所,每个都走。多个库所链接转移,需要都符合条件才可以进行下去。
小练习
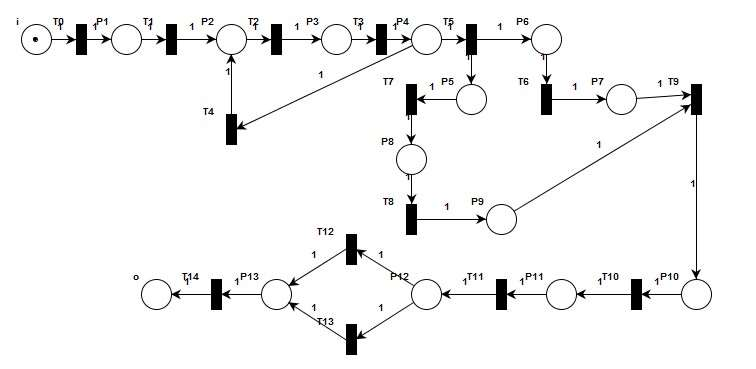
转移图
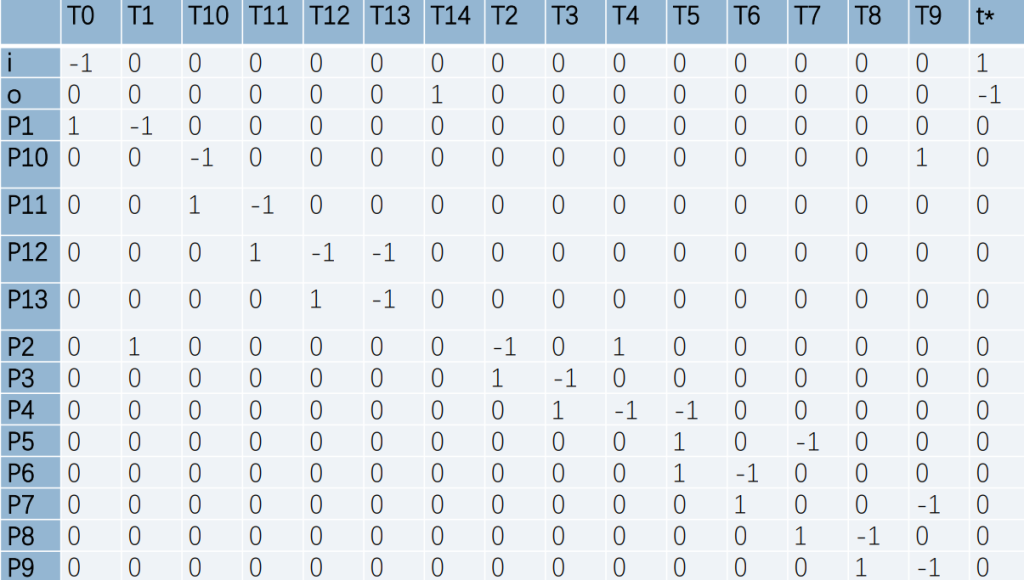
1代表p为t的输出库所,-1代表p为t的输入库所,0代表无联系
流程挖掘及优化
alpha算法
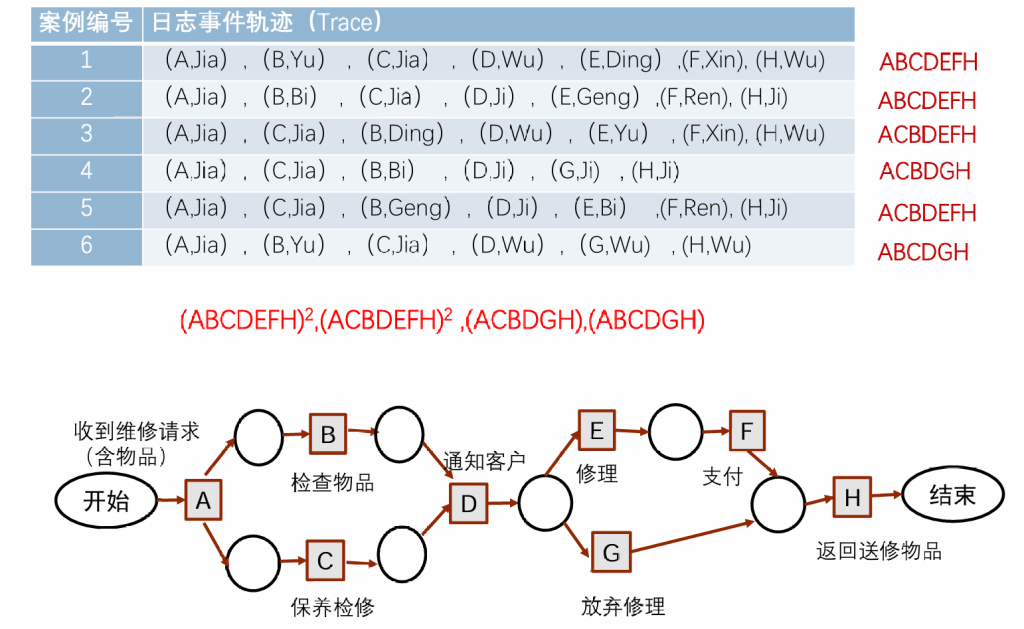
算法不考虑次数,因此对于噪声和不完全性非常敏感
模糊挖掘模糊挖掘(Fuzzy Mining):设定不同的阈值实现多层次活动的生成及展示。
启发式挖掘(Heuristic Mining):将不频繁的路径从模型生成中去掉,建立因果依赖使得模型更好地被表述。
基于区域的挖掘:可以进一步分为基于状态、基于语言等类别,是一种典型的区域挖掘方法。算法核心是发现流程的cursor。
遗传流程挖掘(Genetic process mining):不确定的挖掘方式,通过迭代来模仿自然演变。通过初始化、选择、繁殖、结束等方式实现遗传算法和流程挖掘的结合及应用。
评价体系:
拟合度:对流程的覆盖性
简洁度:简洁度
泛化度:对不在数据范围内的行为的可扩展性
精确度:是否包括过多“不存在”的流程
四种模型:
顺序模型:只描述出现最多的系列,其他作为噪声过滤

花型模型:覆盖所有可能,包括未发现的

枚举模型:

均衡模型:

四种模型比较:

排队论

例题:对于某一task,每小时平均有8个案例到达,每小时平均处理 10个案例。
λ = 8 ; u = 10
p(利用率) = λ / u = 0.8
L = 0.8 / 0.2 = 4
W = 4 / 10 = 0.4h = 24min
S = W + 1 / u = 0.4 + 0.1 = 0.5

WIP:平均队列长度,排队等待的顾客数与正在接受服务的顾客数之和,就是L。